Capabilities You Do Not Own
Twenty years of integration have run on copying data across a boundary. Agentic consumers make that trade worse. Agentic Resource Discovery is the visible half of the response. The runtime layer that has to sit beneath it is the harder half, and data platforms are the most natural place to see it land.
Read this later
We'll send this piece + the next one we publish. No spam. Unsubscribe in one click.

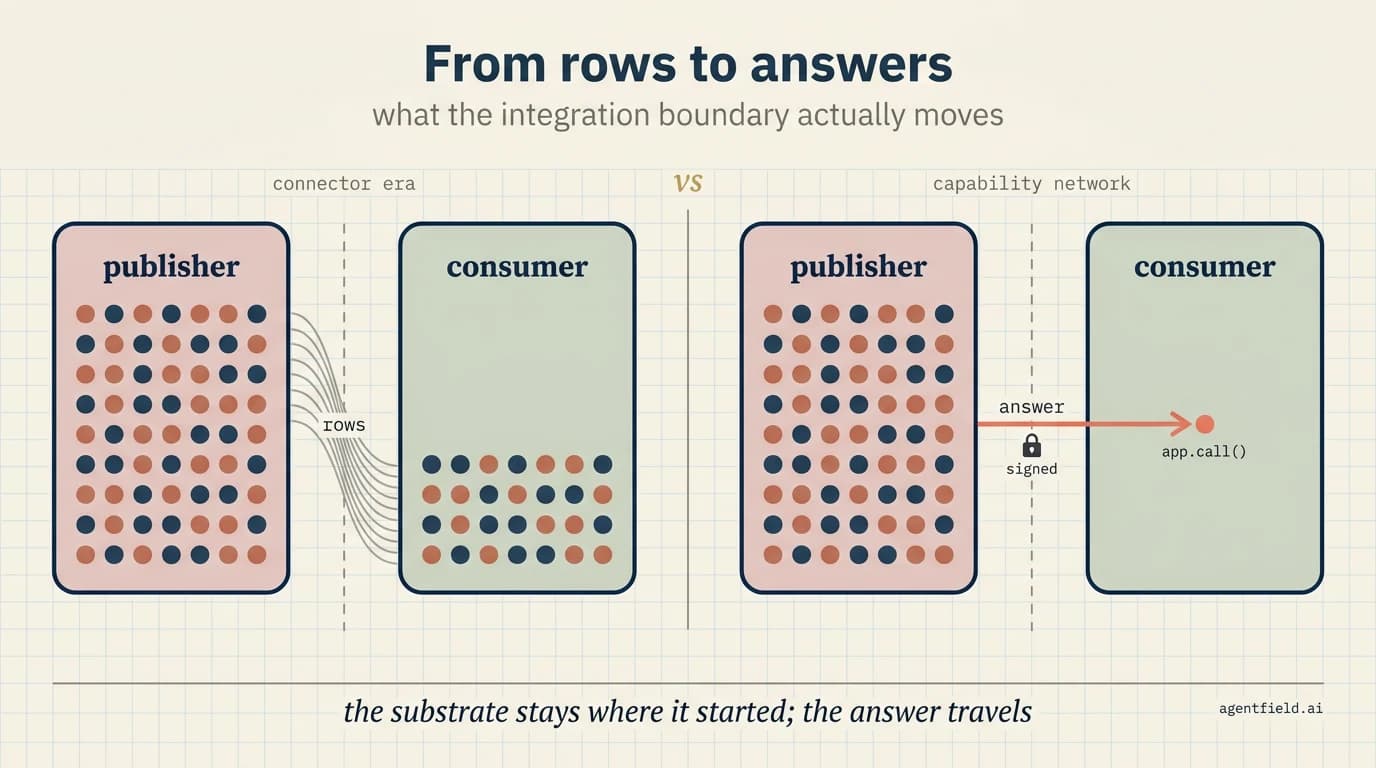
The default integration pattern of the last twenty years assumes that to use someone else's data, you take a copy of it across a boundary. Connectors, ETLs, replication, federation, and shared schemas are all variations on the same trade: the publisher hands rows to the consumer, and the consumer's policy is now responsible for what happens next. That trade was acceptable when the consumer was deterministic code with a known purpose. It gets worse every quarter that agents become a meaningful slice of the consumer side, because the consumer is a reasoning loop the publisher cannot see into and did not authorise.
Everything described in this post is implemented in agentic-resource-discovery-lab, an open-source companion repo we are publishing alongside it. Two AgentField control planes, one ClickHouse, one signed capability call across the boundary. Clone it if you want the technical detail running locally while you read.
The shape the industry has been working toward treats the publisher's side as the home of the conclusion, rather than the source of inputs. The consumer asks a bounded question, the publisher answers it on its own runtime under its own policy, and the data behind the answer never crosses the boundary. The discovery half of this shape has been getting standardised in the open over the last year, most visibly through the Agentic Resource Discovery specification published by Google, Microsoft, and Snowflake. The runtime half is the harder problem. AgentField now speaks ARD natively, and the size of that integration is worth pulling out before anything else.
Why a discovery spec on its own is not enough
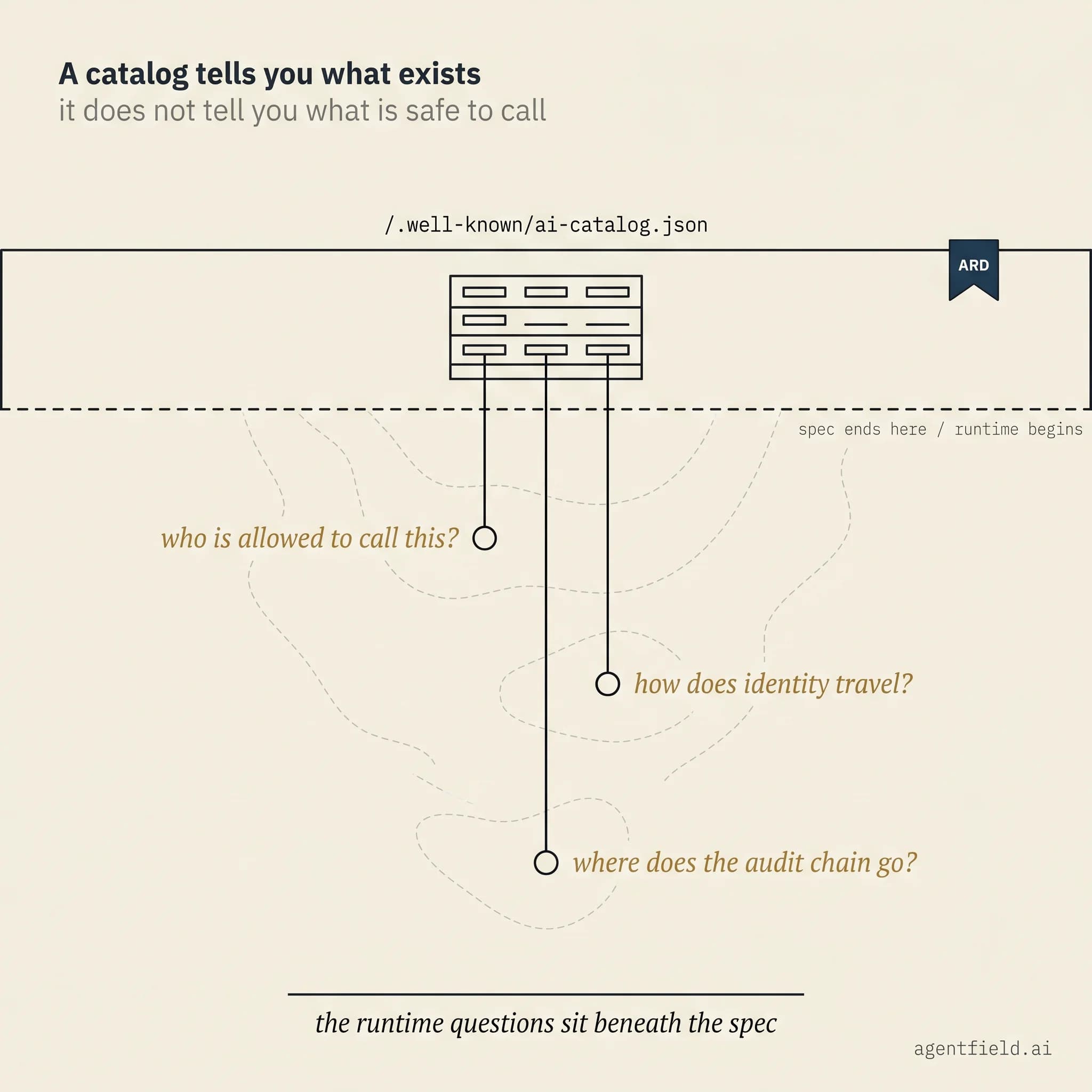
A discovery convention answers one question well: what capabilities are out there, and how would you describe one to a system that has never seen it. ARD does this carefully, with a /.well-known/ai-catalog.json route, structured metadata, identity signals, and a sensible versioning model. The convention is sound. It is also not enough on its own to let one agent runtime act on a capability published by another.
The reason is that the moment a runtime sees an entry in a catalog and considers calling it, the catalog runs out of answers. Is the consumer's workflow allowed to bind to this entry under the policy the consumer's control plane enforces? Does the publisher's runtime have any way to recognise the caller and decide whether to honour the call without relying on a shared identity provider? Will the audit chain that has to survive the boundary do so in practice, or will it terminate somewhere neither side can reconstruct later? These are runtime questions, and they are answered by the system that runs the workflow, not by the system that published the entry.
Most current attempts at cross-runtime composition stall here. The catalog is the part you can see, so the spec work concentrates there. The harder work lives in the runtime the discovered entry has to land on, and that runtime has to have been built with the right shape long before the catalog shows up.
What the runtime layer beneath a discovery spec has to do
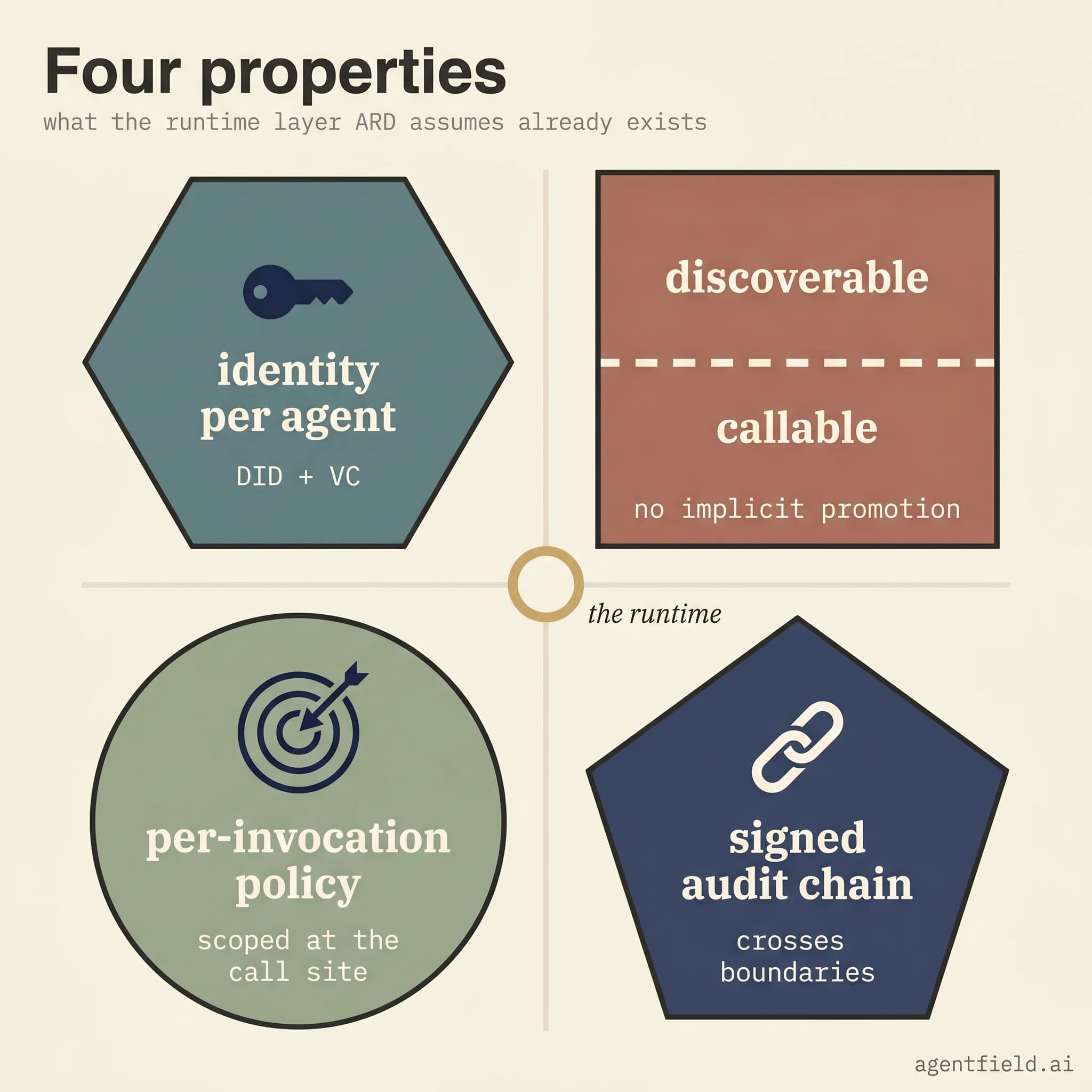
A runtime has to provide four things before a discovery convention becomes useful cross-control-plane composition. None of the four is easy to retrofit.
The first is identity that exists per agent and per reasoner, with a verification model that does not require both sides to share an identity provider. Verifiable credentials over DIDs are how the rest of the web has solved this, because they let two runtimes recognise each other from cryptographic material rather than from a prior contractual relationship. The second is a control plane that draws a hard line between what can be discovered and what can be invoked, with operator-level opt-in on both. The moment those collapse into the same operation, the system is running a public marketplace by accident. The third is per-invocation policy on the consumer side, so a callable import is governed under the same boundary the operator uses for internal agents, instead of under whatever permissions the original token carried. The fourth is an audit chain recorded as workflow steps with cryptographic provenance rather than log lines, because logs end at organisational boundaries and signed credentials do not.
That is the bar a runtime has to clear before a discovery spec like ARD becomes a small protocol change rather than a major rewrite. AgentField has been built on these four properties since its first public release more than a year ago. Adding ARD support came down to a publish route on the well-known catalog, an import flow on the discovery side, and a thin adapter that lets app.call() resolve to a publisher-owned execute URL when the target is an external entry. The architecture underneath was what made the integration small.
What this combination makes practical
With both halves in place, the shape that becomes practical is the one this post's title points at. An agent on one control plane can make real use of a capability owned by an organisation running on a completely different control plane, and nothing sensitive on the publisher's side has to move. The consumer's workflow receives a structured answer rather than rows. The publisher's runtime keeps full control over how that answer is produced and under what policy. Both sides hold an audit chain that survives the boundary, recorded as workflow steps signed by identities the other side can verify locally without phoning home.
The connector era could not produce this shape, because every variation on connectors ends with a copy of the data sitting somewhere it did not start, governed by a policy weaker than the publisher's. Capability publishing keeps the data on the publisher's side and lets only the answer cross.
What capability publishing looks like in practice, with ClickHouse standing in for the general case
The runnable example in agentic-resource-discovery-lab uses ClickHouse because it is open source and the entire two-control-plane setup fits inside one docker compose file. The pattern is the same on any engine where the publisher wants to ship judgment rather than rows.
A market data provider, MarketDataCo, runs a benchmark dataset in ClickHouse. The dataset is the asset. The conclusions drawn from it (the aggregated picture for a given segment, region, and quarter) are the product MarketDataCo wants to sell. Downstream partners want those conclusions inside their own planning workflows without ever touching the warehouse. MarketDataCo publishes a single capability:
market_data.pricing_benchmarkIt takes three arguments and returns an aggregated context object that a downstream agent can compose with.
{
"median_contract_value": 42000,
"p75_contract_value": 51000,
"avg_usage_growth_pct": 18.2,
"sample_size": 4
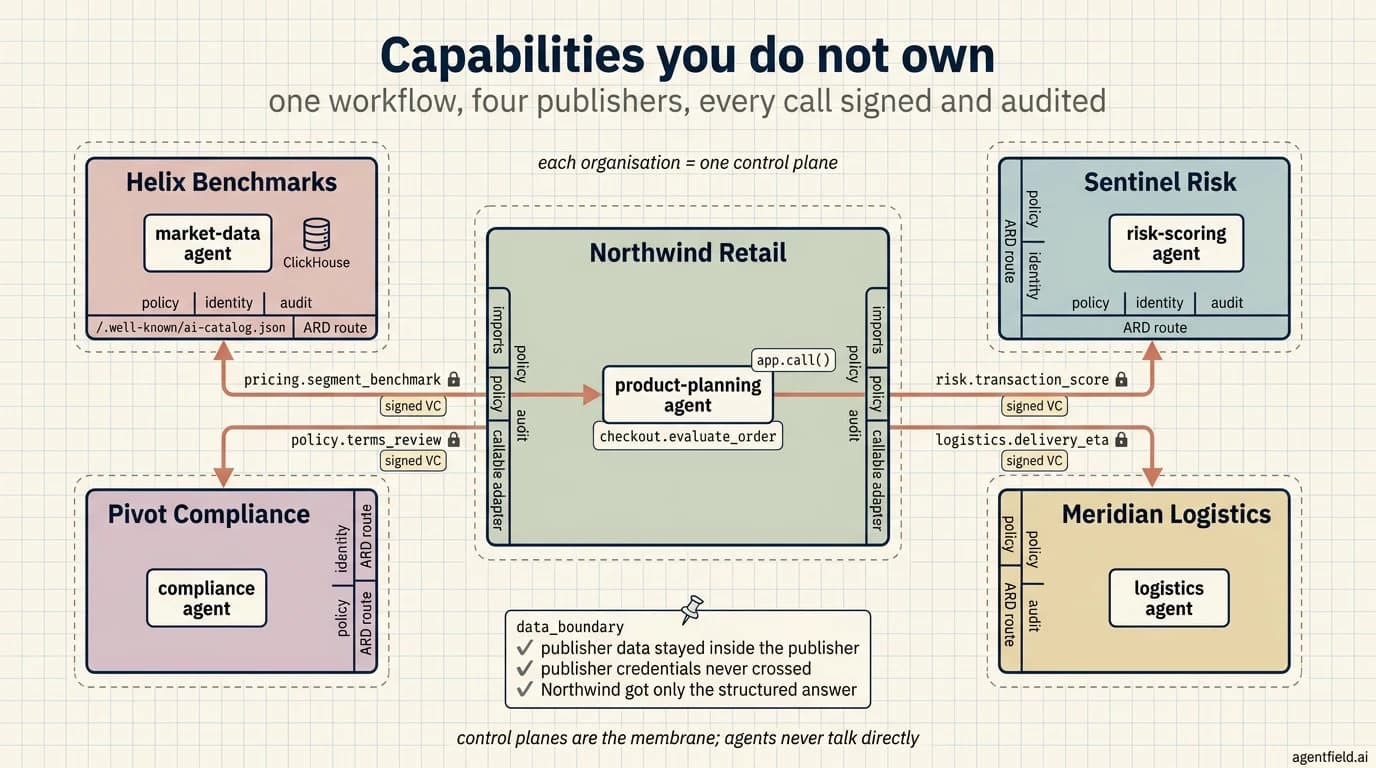
}On the consumer side, a planning team at ProductCo points its AgentField control plane at MarketDataCo's catalog. The ARD entry comes in as a first-class object the operator can act on, and the operator marks it callable through a planning adapter. From there, the capability shows up at a normal app.call() site inside any workflow that has been granted access:
market_context = await app.call(
"product-planning.get_market_context",
segment="smb",
region="na",
quarter="2026-Q2",
)The wrapper resolves to the publisher-owned execute URL from the ARD entry. The request lands inside MarketDataCo's runtime, runs under MarketDataCo's policy, and reaches the ClickHouse instance MarketDataCo owns. The aggregated answer comes back, ProductCo's planning agent composes it into a launch recommendation, and ProductCo never sees the warehouse, the credentials, or the underlying rows. MarketDataCo, on the other side, never sees ProductCo's planning logic.
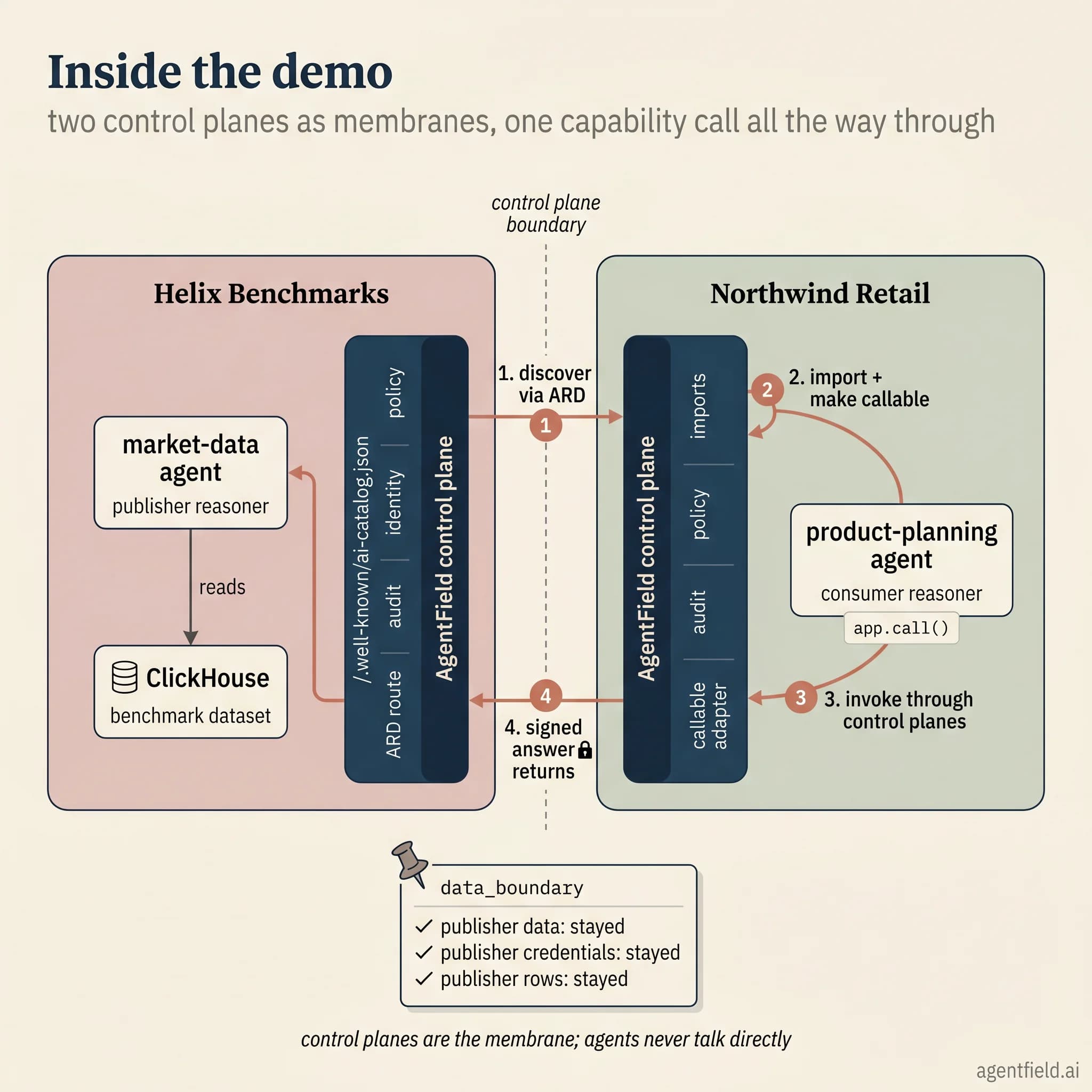
The choice of ClickHouse here is incidental. The same architecture supports the equivalent move on Snowflake, Databricks, BigQuery, or an internal warehouse, and the wider pattern reaches beyond the data platform category entirely.
What this changes for data platforms
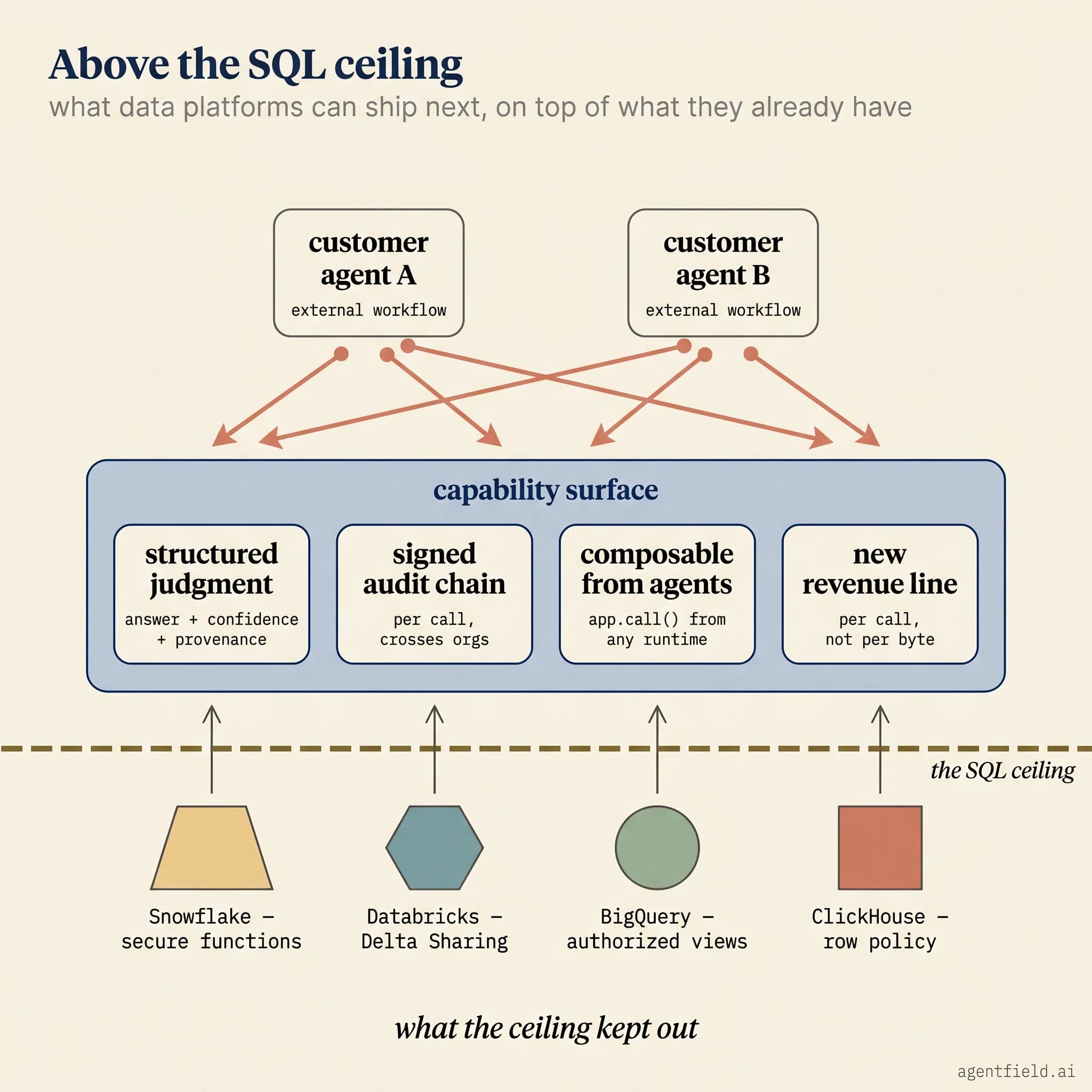
Data platforms are one of several places this layer changes how publishers and consumers transact, and they have the clearest existing precedent in SQL. Snowflake's secure functions, Databricks' Delta Sharing, BigQuery's authorized views, and ClickHouse's row-policy and dictionary patterns are all variations on the question of how to let a consumer ask a bounded question against data they cannot see. The Snowflake and Databricks shapes are also the ones AgentField already exposes as callable capabilities through its Snowflake and Databricks integrations, which is part of why the capability publishing step on top of them feels small rather than disruptive. Each surface works narrowly inside the SQL boundary, and each hits the same ceiling for the same reason: the only abstraction available is a function call governed by a per-grant policy, and an agentic consumer needs something with more judgment in it than a function call carries.
Capability publishing is the generalisation those products have been approximating from below. A reasoner replaces the function and can do what the function cannot, navigating the underlying data, declining when the question is ambiguous, escalating when the policy demands it, and returning structured context that carries its own confidence and provenance. The publisher's existing identity governs trust, in place of a per-query grant, and the audit chain stays cryptographic from the consumer's workflow step through to the underlying execution. For the platforms already hosting the relevant data, this is the move they have been building toward in SQL: a capability surface that runs on their existing trust assumptions, and let customers compose those capabilities into agent workflows the platform did not have to anticipate. ARD provides the discovery half of that picture, and a runtime that already implements the four properties above provides the other half. AgentField is one such runtime, and the data platform shape is the cleanest one to walk through from end to end.
Running the example
agentic-resource-discovery-lab brings up two AgentField control planes (MarketDataCo on 8081, ProductCo on 8082), one ClickHouse instance, and the two agents on either side of the boundary. docker compose up --build boots the stack. A smoke script then walks the lifecycle on both sides. It publishes the capability through MarketDataCo's ARD API, verifies the well-known catalog, searches the catalog from ProductCo's side, imports the result, marks it callable through the planning adapter, and runs ProductCo's planning workflow against the publisher-owned execute URL. The response includes a data_boundary object that records what ProductCo received and, more usefully, what it did not.
Look at the boundary the answer crossed, rather than the recommendation itself.
What this changes for the integration market
The integration market the connector era built was always an export market in disguise. The publisher of the data became, by integration, a supplier of bytes, and the publisher's expertise stopped at the schema. Capability publishing rearranges the trade. The data stays where it is, the expertise crosses the boundary as a callable surface, and the audit chain holds on both sides. The runtime half of this picture has been quietly in place for over a year, and the discovery half has just landed on top of it. The questions worth watching now are which publisher-side teams ship the first capability surfaces, and which of the shapes sketched here matures first.
Code: agentic-resource-discovery-lab · Platform: AgentField · Start building on AgentField
More from AgentField
Read this later
We'll email this article so you can finish it when you have time. You'll also get the next one we publish.
No spam. ~1 email/week. Unsubscribe in one click.