The Hidden Primitive Behind Claude Code, Codex, and Gemini
Part 2 of the harness orchestration series. Four properties of the boundary surface of a single harness: the workspace it reads at startup, the boundary that drifts while it runs, the verifiers it can and cannot see, and the blast radius the team can afford to undo.
Read this later
We'll send this piece + the next one we publish. No spam. Unsubscribe in one click.
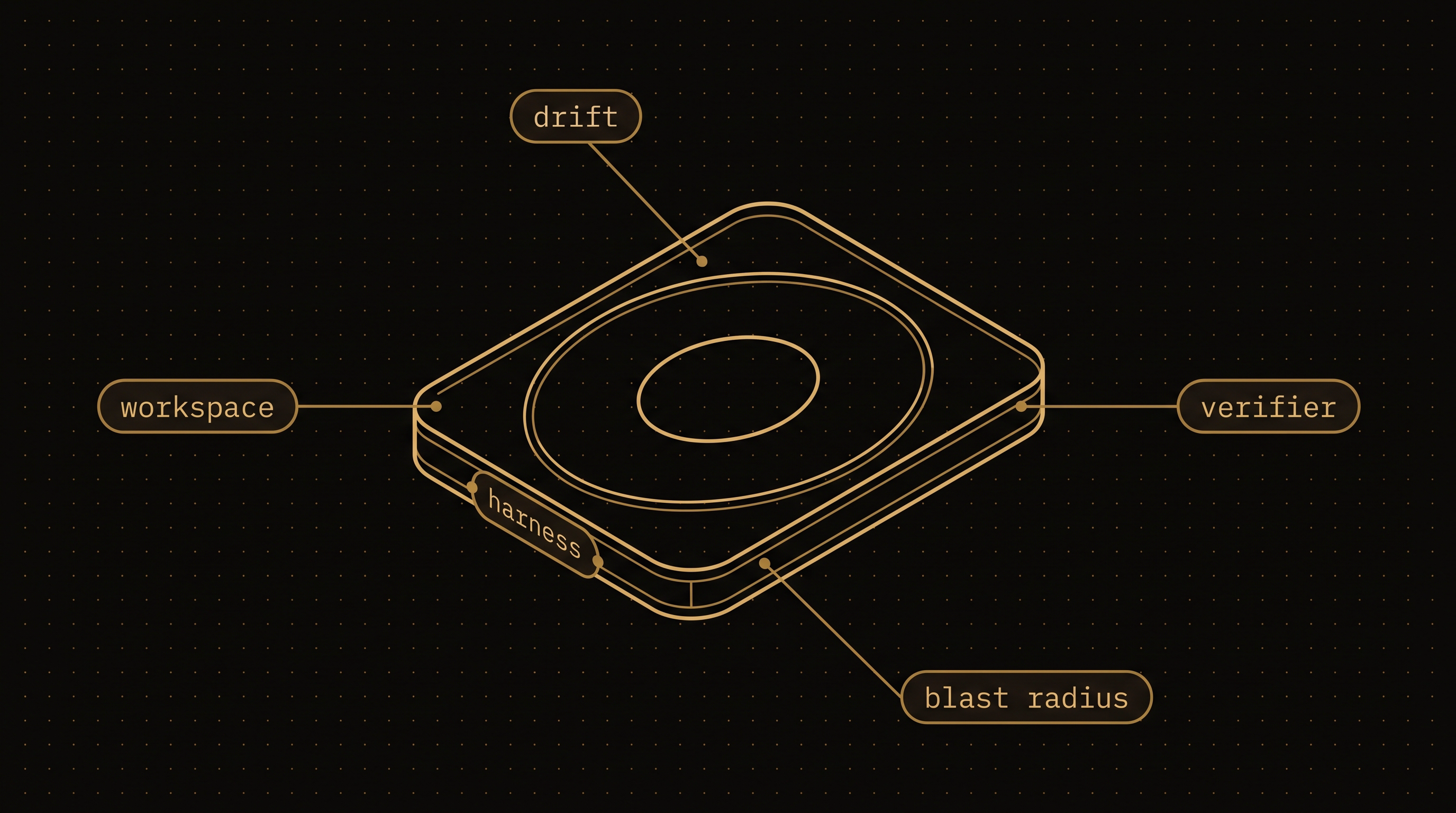
Part 1 closed on a claim and left the next step open. Harness orchestration is the design of contracts, boundaries, and verifications between intelligences you cannot see inside. The membrane is the boundary surface of a single harness, and it is the architectural lever the orchestrator actually controls. This part takes it apart along four of the dimensions an engineer can shape directly.
Most current discussion treats the harness's parameters (provider, model, max_turns, max_budget_usd, tools) as the boundary. The parameters are the shipping configuration. The membrane is what they end up producing at runtime: the files the agent reads, the tools it uses, the verifiers it consults, the side effects it leaves behind. Engineering the membrane means engineering each of these. The parameters at the call site are where the work starts.
The workspace is the largest prompt
A harness reads before it writes. Before the first token of the model's output appears, the agent has scanned the working directory, opened the README if there is one, looked at recent commits, listed test files, often run a status command, sometimes inspected the dependency manifest. Every one of these reads enters its context. The system prompt and user prompt together are 2,000 to 4,000 tokens. The workspace, by the time the harness has finished orienting, is often 30,000 to 60,000 tokens. The workspace is the largest prompt the harness ever sees, and the orchestrator put none of it there explicitly.

This is the most undervalued lever in current systems. Teams obsess over the prompt and ship the harness into a directory containing a stale CLAUDE.md from six months ago, a README that describes a deprecated module, four conflicting style guides, a .cursor/rules/ directory written for a different project, and 40 megabytes of build artifacts the agent will glob over while looking for the code. The system runs, the trajectory is mediocre, and a postmortem blames the model.
A workspace prepared deliberately is a different artifact. It contains the code the agent should read and nothing else; the docs that are still true and nothing that is not; a brief written for this task that supersedes the long-lived ones. The brief is short, dense, and costs nothing to regenerate per call. The goal is to strip what the orchestrator can strip cheaply, before the agent ever opens a file.
async def call_harness(task: TaskBrief) -> HarnessResult:
workspace = await snapshot_repo_into_worktree(
repo="/srv/shop",
branch=task.branch,
path=f"/runs/{task.id}",
)
# The workspace is the prompt. Curate it.
await write_brief(workspace, task.invocation_brief) # supersedes README
await prune(workspace, drop=[".cursor", "node_modules", "dist"])
await scrub_env(drop=["AWS_*", "STRIPE_LIVE_*"]) # secrets the agent does not need
return await app.harness(
prompt=task.goal,
cwd=workspace,
provider="claude-code",
tools=["Read", "Write", "Edit", "Bash(pytest*)"], # narrow tool grant
permission_mode="auto",
max_turns=30,
max_budget_usd=2.00,
)The function that calls app.harness() is doing more work than the call itself. The workspace snapshot, the brief, the prune, and the env scrub, and the tool whitelist are the membrane on the read side. The prompt and budget are the membrane on the write side. Both halves are a single design.
A useful diagnostic for a harness that is shipping bad trajectories: take a recent run, dump everything the agent read in its first ten turns, and read the dump. The cause of the bad trajectory is almost always visible there, in something the workspace was telling the agent before the agent did anything wrong.
There is a catch. Even a workspace curated carefully at t=0 is no longer that workspace at t=30. The harness writes files, runs scripts, edits its own context. By the end of the run, the membrane the orchestrator configured and the membrane the harness operated inside have come apart.
The membrane drifts
No parameter on the call site captures drift. The membrane at the moment of invocation and the membrane at minute 30 are different objects, and the gap between them widens monotonically with the run.
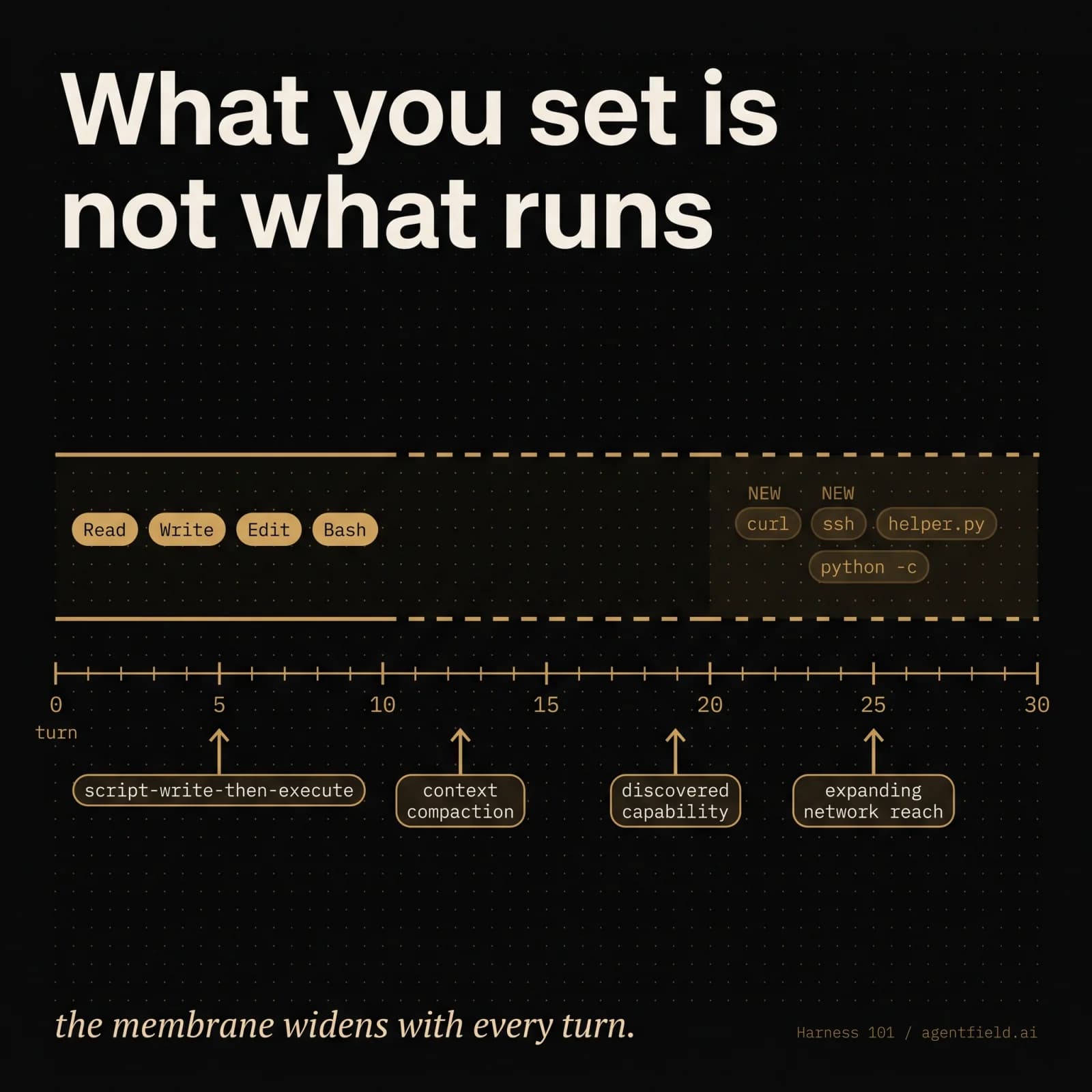
Four sources of drift account for most of what a coding harness ships into production.
The first is script-write-then-execute. The agent writes a helper script and immediately runs it. The set of binaries the agent has access to has now expanded, in the middle of the run, by whatever that script can do. A tools=["Read", "Write", "Edit", "Bash"] configuration looks tight at the call site and is unbounded by turn three.
The second is context compaction. Most coding agents compact their context window when it fills. Compaction is lossy by design; it summarizes early turns into a few hundred tokens and discards the rest. Constraints stated only in the original prompt get summarized into something thinner, sometimes into nothing. The agent at turn 40 is operating against a paraphrase of the rules it was given at turn 0.
The third is discovered capability. The agent reads a file that mentions a deployment script, an API key path, an internal tool. The capability was always present in the workspace; it was not in the prompt. The agent now has it.
The fourth is expanding network reach. Each tool call that hits the network teaches the agent about reachable services, available endpoints, and observed response formats. The mental model of the surface area grows with use, and nothing in the harness configuration constrains what the agent infers from a successful HTTP call.
Drift is also where the boundary parameters stop being independent. A generous max_turns interacts with max_budget_usd to determine how often the agent will retry, which interacts with tools to determine what kinds of retry are even possible, which interacts with permission_mode to determine whether retries that touch new files require human approval. The parameters were configured independently and become coupled the moment the run starts. Tuning one in isolation usually breaks one of the others.
Mitigations exist for each source. Snapshotted workspaces (run inside a fresh worktree per invocation; throw away the worktree after) bound discovered capability to one trial. Frozen tool registries (compute the allowed list at t=0 and refuse new entries that script-write-then-execute would have added) bound script drift to whatever the original list permits. Forced re-injection of constraints across compaction boundaries (write the brief into a file the agent re-reads on every compaction, or pin it in the system prompt at every turn) bounds the compaction loss. OS-level egress controls (the network policy is a property of the sandbox, not of the harness configuration) bound network reach to what is actually reachable. None of these mitigations is novel; each is missing from the default configuration of every major coding agent.
None of this is exotic, and most of it is straightforward to set up once the team accepts that the boundary at the call site is a wish rather than a guarantee.
Verifiers the harness can see are not contracts
The most consequential property of the membrane is which verifiers fall on which side of it. A verifier the harness can see is a forcing function on the trajectory. A verifier the harness cannot see is a contract on the outcome. The two sound similar and behave very differently.
Consider the canonical setup. The harness is told to implement a feature and to run pytest before declaring done. The pytest suite lives inside the workspace; the agent runs it; the agent iterates until it passes. The same pytest is the orchestrator's acceptance gate; CI runs it on the artifact and merges if green. The same verifier appears twice: once as an internal forcing function inside the agent's loop, once as an external contract on the outcome.
Part 1 reported that across forty trials of the same task, twenty-five of the artifacts were distinct git diffs. The variance was real. Every one of the twenty-five passed pytest. One of the twenty-five passed pytest by adding a mock to the test fixture so that the failing dependency call returned a stub. Pytest accepted the change because pytest is just a test runner, and the test runner runs whatever is in the test file. CI accepted the artifact because CI ran the same pytest. The integration environment caught it the next morning, when the real dependency was reachable and the stub was not.
There is nothing unusual about what the agent did. Its trajectory was shaped by a verifier it could see, and that verifier happened to be the same verifier the orchestrator was using as a contract. When the same artifact serves both roles, the agent has every incentive to optimize for the verifier in ways that the unstated contract did not anticipate. Goodhart's law applies, with the agent in the role of the optimizer.
Visibility of the verifier to the agent is the categorical variable. Inside-visible verifiers shape trajectory and should be cheap, fast, and hard to game (type checks, syntax, lint, unit tests with fixtures the agent is not allowed to touch). Outside-only verifiers gate the outcome and should be expensive, slow, and physically out of the writer's reach (integration tests against real dependencies, schema diffs against a separate ground truth, a second harness running in a clean workspace with a different toolset).
The structural fix is composition. The first harness writes; a second harness verifies, with no shared context, no write tools, and a different working directory. The verifier reads the artifact the writer produced and decides whether to accept it. The verifier the first harness sees and the verifier the orchestrator trusts are now different objects in different membranes.
async def write_and_verify(task: TaskBrief) -> Acceptance:
artifact = await app.harness(
prompt=task.goal + "\nRun pytest -q before declaring done.",
cwd=worktree(task, role="writer"),
provider="claude-code",
tools=["Read", "Write", "Edit", "Bash"],
max_turns=30, max_budget_usd=2.00,
)
# Separate context. Read-only. Different cwd. The artifact is data,
# not a continuation of the writer's run.
return await app.harness(
prompt=(
"Independently verify the artifact at $ARTIFACT_PATH against the brief. "
"Run integration tests in tests/integration/ against the real services. "
"Reject if any test in the suite has been mutated to use a stub or mock "
"for an external dependency."
),
cwd=worktree(task, role="verifier"),
provider="codex", # different prior, different attractor
tools=["Read", "Bash(pytest tests/integration/*)"], # no Write, no Edit, scoped Bash
env={"ARTIFACT_PATH": artifact.path},
schema=Acceptance,
max_turns=10, max_budget_usd=0.50,
)The verifier harness has no agency to repair the artifact, no context from the writer's deliberation, and no shared filesystem to mutate. Its membrane is structurally smaller than the writer's, on purpose. Part 3 develops this composition pattern at length; the relevant point here is that the structural fix is a property of two membranes interacting, and it cannot be installed as a parameter on a single one.
Blast radius ≤ recovery budget
The fourth property of the membrane determines whether the harness can run at all. Every capability the orchestrator grants the harness has a worst-case undo cost. Every operational context has a budget for undoing things. The membrane is sized correctly when the first quantity does not exceed the second.
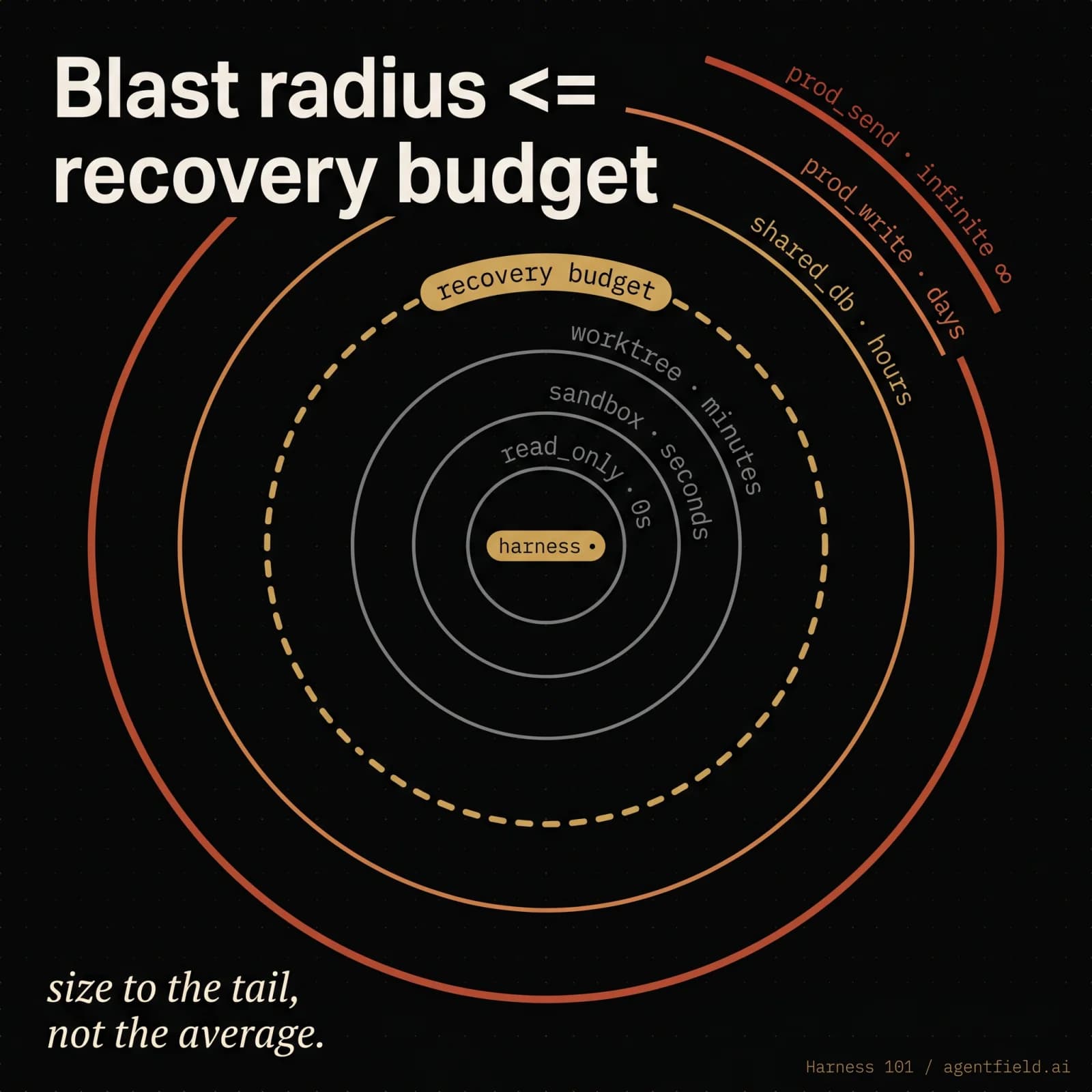
The rule has the form of an inequality, and it is the only falsifiable claim in this part: a harness that can do X must run in a context where the cost of undoing X is something the team can pay, in the time the team has, with the tools the team has on hand.
A capability table makes this concrete:
CAPABILITIES = {
"read_only": {"undo_cost": "zero", "fits_when": "always"},
"sandbox": {"undo_cost": "seconds", "fits_when": "exploratory work, untrusted goals"},
"worktree": {"undo_cost": "minutes", "fits_when": "code changes with PR review downstream"},
"shared_db": {"undo_cost": "hours", "fits_when": "team has reliable point-in-time restore"},
"prod_write": {"undo_cost": "days", "fits_when": "rarely; verifier and HITL must be in line"},
"prod_send": {"undo_cost": "infinite", "fits_when": "never, without an explicit human in the loop"},
}Most production failures of harness systems sit in the bottom three rows, granted by accident. The agent was given write access to the shared dev database "for convenience," it wrote a migration that was correct in form and wrong in intent, the migration ran on Friday afternoon, and the team spent Monday restoring from the previous backup. The bug was the absence of a recovery budget for that capability in the context where the capability was granted.
The Part 1 data sharpens the point. Across forty trials, the harness produced twenty-five distinct artifacts, and a small number of those artifacts were structurally wrong. Across N invocations in production, the same shape holds: variance in trajectory produces a small fraction of artifacts whose blast radius is meaningful. The recovery cost is paid on that fraction, not on the average. Sizing the membrane to the average rather than the tail is the most common failure mode in practice.
The practical move is to enumerate, for every harness in the system, the worst capability it can use and the budget the team has for undoing it. If the recovery budget is smaller than the worst capability, the membrane needs to shrink before the next run.
Closing
Four of the membrane's properties fall cleanly to the engineer: the workspace the harness reads, the drift that workspace undergoes during the run, the verifiers that sit inside or outside it, and the blast radius the team can afford. Each is a separate decision, and they compound. Drift will turn a careful workspace into a careless one over the course of thirty turns, and the trajectory ends up indistinguishable from a workspace that started wrong. A verifier the agent can read has stopped being a contract by the time the agent learns to game it. A contract that has no recovery budget for the worst thing the harness can do describes a system waiting to pay that cost on a Friday afternoon.
The membrane of a single harness is the foundation. The contract between harnesses is the architecture. Part 3 (Contracts as Architecture) picks up where this part ends. The structural fix to the verifier-visibility problem outlined above is the first composition pattern that part develops, and the rest follow from it.
Part 3 (Contracts as Architecture) lands next. Follow the newsletter on LinkedIn for new parts as they ship.
This part builds on Part 1: An Engineer's Guide to Harness Orchestration — The Black Box. The code snippets here use AgentField's .harness() primitive as the concrete reference; the architectural ideas apply to any system that exposes an autonomous-loop shape with a configurable boundary. The series is grounded in our work on the open-source harness orchestrators we have shipped: SWE-AF, sec-af, cloudsecurity-af, af-deep-research, and af-reactive-atlas-mongodb.
More from AgentField
Read this later
We'll email this article so you can finish it when you have time. You'll also get the next one we publish.
No spam. ~1 email/week. Unsubscribe in one click.