An Engineer's Guide to Harness Orchestration
Why orchestration changes when the unit decides for itself. The harness is a fundamentally new kind of computational object, defined by agency, embodiment, and persistence in one primitive. Part 1: The Black Box.
Read this later
We'll send this piece + the next one we publish. No spam. Unsubscribe in one click.
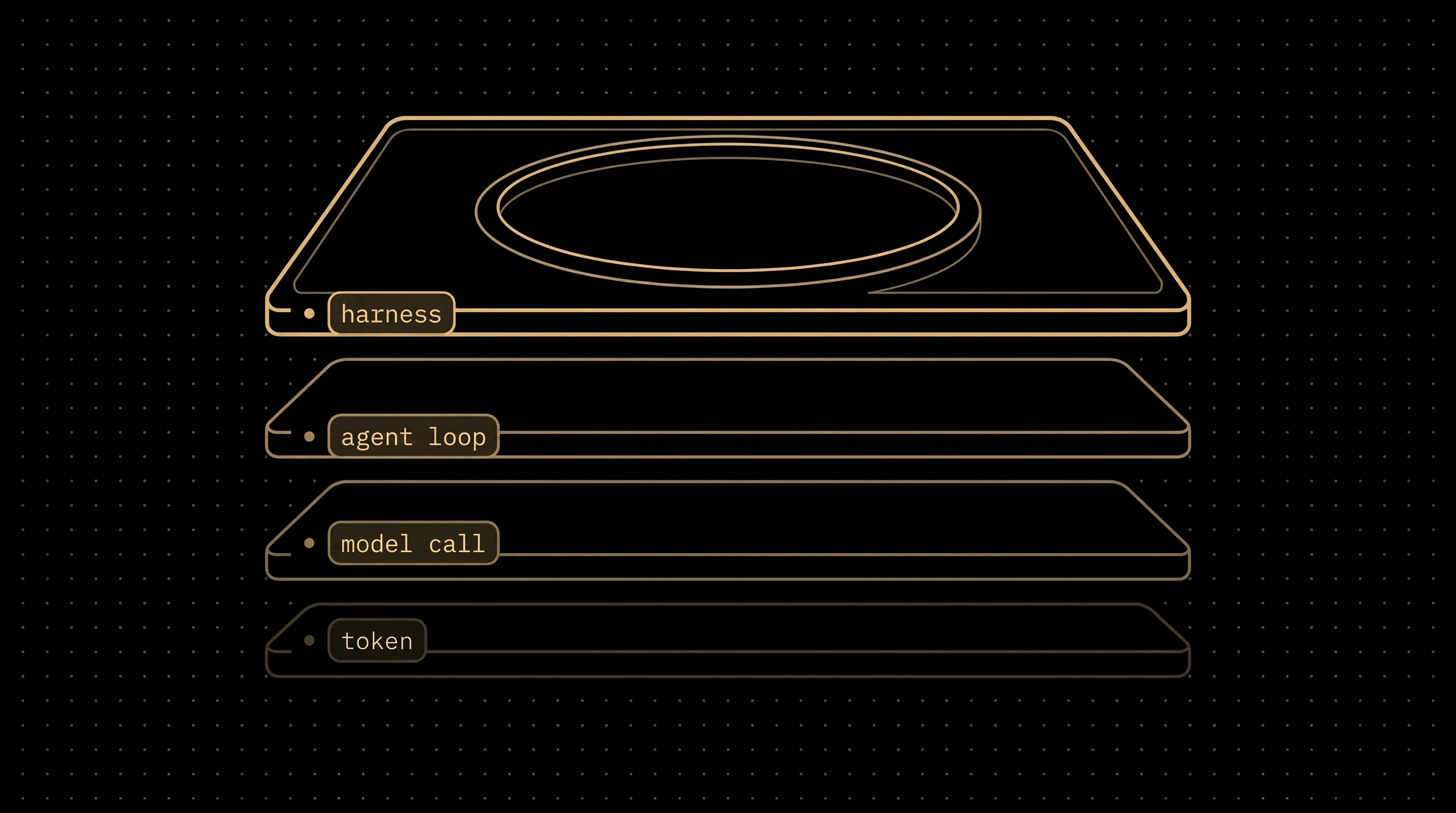
The atomic unit of intelligence has climbed. A token. A model call. An agent loop. A harness. Each level absorbed the complexity below it and presented a different contract upward. Most of the orchestration discourse in 2026 still operates at the model-call level, treating intelligence as a function the orchestrator drives step by step. The patterns built for that world (prompt chains, output parsers, tool-use graphs) do not transfer to the next level, and the gap is the source of most architectural confusion in modern AI systems.
We have spent the past year building harness-based orchestrators across several domains: SWE-AF for autonomous software engineering, sec-af for security auditing, cloudsecurity-af for cloud infrastructure security, af-deep-research for autonomous research, and af-reactive-atlas-mongodb for reactive data enrichment. Each composes harnesses to do work that previously required dedicated engineering teams, and each is built on top of the same small set of primitives. The patterns in this series are the discipline we extracted from those builds: the architectural shapes that show up across every domain once the harness becomes the unit of work.
This is the first in a five-part series. It argues that the harness is a fundamentally new kind of computational object, that orchestration around it is closer to organizational design than to software engineering, and that the architectural patterns that follow are not borrowed from cloud-native or distributed systems lineages. They are derived from what the harness primitive actually is.
Part 1 establishes the foundation. The remaining parts build the discipline on top of it.
Two shapes of call
There are two natural shapes for using intelligence in an application. The first is a constrained call: single-shot, structured input and output, no tools, no iteration. The second is an autonomous loop: goal in, environment access, multi-turn execution, verified outcome out. They have different costs, different failure modes, different rules of engagement. Most orchestration questions reduce to which shape a given step wants, and the answer is rarely ambiguous once the framing is right.
The constrained call:
class IssueClassification(BaseModel):
severity: Literal["low", "medium", "high"]
needs_deeper_review: bool
summary: str
result = await app.ai(
system="Classify this issue.",
user=issue_text,
schema=IssueClassification,
model="openai/gpt-4o-mini",
)
# result is an IssueClassification object.
# Predictable latency. Predictable cost. No tools, no memory, no iteration.A constrained call is one shot at the model. Text in, parsed object out. The orchestrator decides what to do next. The model itself has no agency over the conversation; every decision lives in the orchestrator that called it. (In AgentField, this is the .ai() primitive shown above.)
The autonomous loop:
result = await app.harness(
prompt=(
"Implement JWT authentication on the /checkout endpoint. "
"All tests in tests/test_auth.py must pass. "
"Run `pytest -q` before declaring done."
),
cwd="/srv/shop/worktree-jwt",
provider="claude-code",
model="anthropic/claude-sonnet-4-5",
max_turns=30,
max_budget_usd=5.00,
)
# result.parsed | result.cost_usd | result.num_turns | result.is_errorA harness accepts a goal and a working directory. It launches an autonomous coding agent (Claude Code, Codex, Gemini CLI, OpenCode, and similar systems) inside that directory and returns when the agent declares done or hits a budget. Internally it reads files, writes code, runs commands, retries when tests fail, decides when to stop. The orchestrator does not see those decisions happen. It sees the goal go in and the result come out. (AgentField exposes this as the .harness() primitive shown above; the same shape applies to any autonomous coding agent invoked from a backend.)
The two shapes look superficially similar. They are not similar. The difference is the entire subject of this series.
Three properties that distinguish a harness
A harness intelligence differs from an LLM intelligence on three orthogonal properties of the unit. Each one is a yes/no question about what the unit is allowed to do.
| Constrained call | Harness | |
|---|---|---|
| Initiates work? | No, it is invoked | Yes, it decides |
| Acts on the world? | No, it produces tokens | Yes, it writes files, runs processes, hits APIs |
| Carries state across time? | No, it is stateless | Yes, the filesystem, memory, and identity persist |
These three properties (call them agency, embodiment, and persistence) are independent. A primitive can have any subset of them. The Cartesian product produces eight cells, and the cell where all three are present is the cell that no prior software primitive has occupied. A function has none of them. A microservice has embodiment and persistence but not agency. An LLM call has none. An agent loop has agency but not durable embodiment or persistence beyond the call. Only the harness has all three together, and it is the simultaneous presence of all three that produces every architectural concern in this series.
The combination matters because the consequences are coupled. A unit that only had agency without embodiment could decide things but could not act, so its blast radius would be zero. A unit that only had embodiment without agency would act, but only when invoked, so it would be a regular service. A unit that only had persistence would carry state, but without agency or embodiment it would just be a database row. The harness's properties compound. Each property amplifies the architectural weight of the others.

Variance absorption
The single most useful property of a harness, the property that justifies the cost difference, is what we will call variance absorption. It is the capacity to handle a distribution of related problems without changing the call site or the configuration.
Consider the same harness invocation pattern applied to three different tasks against the same codebase:
fix_bug = await app.harness(
prompt="Fix the failing test in tests/test_auth.py. Run pytest -q to verify.",
cwd=repo,
provider="claude-code",
)
add_feature = await app.harness(
prompt="Add a /healthcheck endpoint that returns DB and Redis status. "
"Add a happy-path test in tests/test_health.py.",
cwd=repo,
provider="claude-code",
)
refactor = await app.harness(
prompt="Extract the email-sending logic from app/notifications.py into "
"app/email/sender.py. Keep the public API stable. "
"All tests must still pass.",
cwd=repo,
provider="claude-code",
)Three completely different tasks. The same call shape. The same primitive. The variance lives in the prompt and the workspace state; the harness absorbs it into appropriate trajectories. There is no second call site for fixing bugs versus refactoring versus adding features. There is no agent-pipeline-per-task-class architecture to maintain. The harness, conditioned at runtime by the prompt and the codebase it inhabits, becomes the appropriate worker for whichever problem arrives.

This is structurally impossible for any prior primitive. A function expects fixed inputs. A microservice expects a fixed schema. An agent pipeline is engineered for a specific task class. A harness is engineered for a distribution of task classes, and the distribution is part of its design.
Variance absorption has two axes. The model contributes one. A frontier model can absorb a wider distribution of problems than a smaller model, given the same prompt and tools. The harness design contributes the other. A well-designed harness with a tight prompt, a curated tool set, and a focused workspace can absorb a wider distribution than a poorly-designed one running on the same model. The two axes compound. Most teams treat model selection as the primary lever and design as secondary. The two axes are equally weighted, and the design axis is more under your control.

This is why, on a standardized benchmark we ran across two different models, the same architecture scored 95 out of 100 on both Claude Haiku and a far cheaper open-source model: the architecture absorbed the variance the model could not, and verification compensated for the model gap. The architecture is the variance absorption capacity made concrete. The model contributes; it does not dominate.
There is, of course, a cost. Each invocation samples a path from a distribution. Two invocations of the same harness on the same input rarely produce identical bytes. We confirmed this empirically: across forty trials of the same task on the same model on a fresh sandbox, we observed twenty-five distinct git diffs. None of the trials produced the same bytes as another, with one exception that recurred nine times. Every trial passed the verifier. The bytes diverged; the outcomes converged.

The chart above is the empirical foundation of this series. It is the picture of variance absorption working as designed. The trajectory variance is real. The outcome variance, after verification, is essentially zero. The verifier projects the high-variance trajectory space onto a low-variance outcome space, and that projection is what makes harness orchestration tractable. Without it, the variance would be chaotic. With it, the variance is the source of the harness's flexibility.
The same data also reveals something subtle. One particular diff (the hash 7a29755d) recurred nine times across forty trials. Other diffs recurred two or three times. Nineteen diffs appeared exactly once. The distribution of harness output is not flat. The model has attractor states: solutions it returns to under the prior shaped by training. The full distribution has a small number of high-mass attractors and a long thin tail of variants.

Attractor states are a property of the underlying primitive. They are not accidents. They are the model's prior asserting itself across independent invocations. This is unique to harness systems, because no prior software primitive has a prior. A function does not have a default behavior beyond what its code specifies. A harness does. The architectural consequences of attractor states will surface throughout the series.
The black box and the membrane
The harness's most important property, from an orchestrator's point of view, is what it does not expose.
Inside a harness, the model deliberates. It reads files, considers approaches, tries one, observes the result, tries another. Tokens flow. Tool calls fire. Decisions are made. None of this is observable in real time from outside the boundary. The orchestrator that called app.harness(...) sees the goal go in and the HarnessResult come back. The trajectory between those two events is closed.
Calling this a black box is technically accurate but pedagogically misleading. A black box implies binary opacity: either fully visible or fully closed. The reality is sharper. The harness has a membrane. Like a cell membrane, it is selectively permeable. Some things cross freely (the goal, the boundary configuration, the structured outcome). Some things require active work to cross (decision rationales, partial state, intermediate observations, captured in the journal that opencode and similar agents emit). Some things never cross (the model's internal token stream during deliberation, the transient working memory that gets recompacted as context fills).
Designing the membrane is the architectural work. The inside is the harness's. The outside is the system's. The membrane is engineered on both sides: what the orchestrator sends in (prompt, working directory, tool whitelist, time and cost budget), and what it expects back (artifacts, attestation, journal, typed outcome).

This is the deepest reframe of the series. Harness orchestration is the design of contracts, boundaries, and verifications between intelligences you cannot see inside. Architecture stops being "how do I write the workflow that drives the LLM" and becomes "how do I design the joints between intelligent entities I cannot watch." The closer organizational analog is hiring and managing employees: you cannot program their thoughts, you can only set roles, contracts, review processes, escalation paths, and trust boundaries. That analog is not decoration. It is load-bearing. Every architectural principle in this series follows from accepting it.
What changes for the orchestrator
When the orchestrator is driving a constrained call, it is in the role of a programmer working with a powerful function. The orchestrator decides what to ask, when to ask it, what tools to provide, how to interpret the response. The relationship is unidirectional and tight. Prompt chains, ReAct loops, retrieval-augmented generation, output parsers: all of these are patterns for orchestrating from above. They presume the orchestrator controls every step.
When the orchestrator is driving a harness, it is in the role of a manager working with an autonomous worker. The orchestrator does not control the steps. It defines the goal, sets the boundary, and verifies the outcome. The relationship is bidirectional and loose. The patterns from the previous era do not apply. Trying to use them produces a system that has paid for autonomy and refused to use it.

This shift has three immediate consequences:
First, process control gives way to outcome verification. The orchestrator cannot assert that step three of the harness's trajectory was correct, because it cannot see step three. It can only assert that the final artifact passes the verifier. This forces the verifier to become the contract. Whatever the verifier checks, the harness is held to. Whatever it does not check, the harness is not reliably held to.
Second, prompt engineering gives way to membrane engineering. The orchestrator's primary lever stops being the words inside the prompt and starts being the structure of the boundary: which tools the harness has, which working directory it inhabits, what budget it operates under, what success criteria it must meet. The prompt still matters. It is no longer the only lever, and it is rarely the most important one.
Third, the orchestrator becomes a supervisor. It no longer specifies the work; it specifies the conditions under which the work is done and the conditions under which it is accepted. This is a different mental model. It comes naturally to engineers who have managed teams. It feels strange to engineers who have only managed code.
Each of these consequences will be developed in subsequent parts of the series.
What this series explores
Five parts in total, each addressing a different layer of the discipline.
Part 2, Engineering the Membrane, goes deep on the boundary surface of a single harness. The working directory, the budget, the turn limit, the provider, the model: these parameters are the lion's share of the harness's behavior. The prompt is on top of these decisions, not under them. We will look at how to think about each parameter, what good and bad configurations look like, and why narrowing the boundary is more often the right move than broadening it.
Part 3, Contracts as Architecture, moves from a single harness to compositions of harnesses. The contract between two harnesses (the artifact one produces and the next consumes) is the entire architectural decision. We will work through coupling modes (sequential, parallel-with-verifier, adversarial, specular, hierarchical), with code, and show why parallel composition is more reliable than sequential composition for stochastic units, a result that directly inverts microservice intuition.
Part 4, Generative Pipelines and Variance Absorption, is the central intellectual move of the series. Harness pipelines are self-modifying. The structure of the pipeline at minute 30 is generated by the work that happened at minute 0. A planner harness emits a structured plan; the orchestrator instantiates downstream harnesses from that plan; those harnesses can themselves be planners. The pipeline grows. We will look at how this is closer to biological development than to engineering pipelines, and how to keep it predictable through bounded grammars rather than fixed structures.
Part 5, Operating Opaque Intelligence, addresses what happens when a harness system runs in production over weeks and months. We will catalog the failure modes that no prior software has (goal drift, verifier gaming, sycophancy cascades, sleeping bugs from model drift, attractor collapse) and the defensive architecture for each. The premise is that audit and observability cannot be retrofitted onto a harness system. They have to be designed in from the moment the orchestrator decides what to keep from each invocation's outcome and what to discard.
The five parts are independent enough that each can be read alone. They build on each other for the reader who wants the full picture. The order is bottom-up: a single harness, then its boundary, then composition, then pipeline growth, then long-term operations.
Part 2 (Engineering the Membrane) lands next. Follow the newsletter on LinkedIn for new parts as they ship.
Closing
The argument of Part 1 is simple. The harness is not an LLM with extra features. It is a different kind of computational object, defined by the simultaneous presence of agency, embodiment, and persistence. Its central capacity is variance absorption: a single primitive that handles a distribution of related problems, conditioned at runtime by prompt and workspace, with the verifier projecting trajectory variance onto outcome equivalence. Its central architectural property is the membrane: a selectively permeable boundary that the orchestrator engineers but cannot peer through.
Once those two properties are accepted, the rest of the discipline follows. Boundary engineering is the most underused architectural lever in current systems (Part 2). Composition is the inverse of microservice composition, with verifiers as joins (Part 3). Pipelines are generative, not declared (Part 4). And operations require designing for failure modes that have no precedent in deterministic systems (Part 5).
The discipline is new. It is not a renaming of cloud-native architecture, and the patterns that worked at the model-call level do not transfer cleanly. The architectural primitives that follow are derived from what a harness actually is, and the rest of this series is the derivation.
This series is grounded in our work on the open-source harness orchestrators we have shipped: SWE-AF, sec-af, cloudsecurity-af, af-deep-research, and af-reactive-atlas-mongodb. The code snippets here use AgentField's .ai() and .harness() primitives as the concrete reference; the architectural ideas apply to any system that exposes the constrained-call and autonomous-loop shapes. For the underlying argument about why the atomic unit of intelligence is moving up the stack, see What Changes When the Atomic Unit of Intelligence Is No Longer an API Call. For the practical experience that informs these patterns, see How We Ship Production Code with 200 Autonomous Agents.
More from AgentField
Read this later
We'll email this article so you can finish it when you have time. You'll also get the next one we publish.
No spam. ~1 email/week. Unsubscribe in one click.