What Breaks When AI Makes a Trillion Decisions
The world makes hundreds of billions of API calls every day - Cloudflare alone reports processing over 50 million HTTP requests per second at peak. Each call carries a decision: where to route, what to return, how to handle failure. Most of these decisions are hardcoded into configuration files and compiled binaries. But that's starting to change, and the infrastructure isn't ready.
I've been thinking about this for the past year. Our open source work at AgentField.ai has led to conversations with enterprise leaders and developers building these systems, and a pattern keeps emerging. Teams start by asking about orchestration and capabilities, but within a few months the questions shift to accountability, debugging, and cost. The infrastructure gaps become real once you move past the prototype stage.
Agent-style AI systems making contextual judgments at runtime
A clarification on what I mean by "agents" here. I'm not talking about workflow automation that chains LLM calls in predetermined sequences, or the no-code platforms that let you build decision trees with AI at each node. Those tools are useful, but they're essentially DAGs (directed acyclic graphs) where the execution path is defined before anything runs. What I'm describing is software that makes contextual judgments at runtime, where the path through the system emerges from the situation rather than being specified upfront. Think of an order routing agent that evaluates real-time constraints and decides how to fulfill a request, rather than one that follows a predefined flowchart with some AI-powered steps. That distinction matters because the infrastructure challenges are different, and mostly unsolved.
The Scale We're Talking About
A single e-commerce checkout can trigger dozens to hundreds of service calls, depending on architecture: inventory check, payment authorization, fraud scoring, tax calculation, shipping quotes, address validation, order creation, notification dispatch. In large-scale systems, each of these calls fans out to others. It's common for a single gateway request to generate several downstream calls before completing.
Every one of these calls contains a decision. Which warehouse should handle the order? How should the system retry if something fails? What's an acceptable wait time? Today, those decisions are static: configuration files, feature flags, if-else statements compiled into the binary months ago.
Something is shifting, and it's not about chatbots. It's what's happening deeper in backend systems, where decisions that were hardcoded are becoming dynamic. An order routing service that weighs a dozen real-time factors instead of following a priority list. A payment retry strategy that adapts to context instead of following exponential backoff. A notification system that decides not just what to send, but when and how.
Call it the AI backend: reasoning that operates as infrastructure rather than a standalone product. When this scales, things break in ways our current systems weren't designed to handle.
The Pattern We've Seen Before
As web applications grew complex, we extracted databases so business logic didn't have to manage file persistence. Scale brought caches. Real-time requirements brought queues. Each layer abstracted a capability that became too complex and too critical to leave embedded in application code.
We're about to extract another layer. Call it the decisioning layer: AI as infrastructure that runs beneath your services, making contextual decisions that used to be static. The abstraction shifts from hardcoded rules to policies. Instead of "if customer tier equals premium, discount equals 10 percent," you get "minimize delivery time while respecting these constraints, given this context."
Redis started as a caching tool and became foundational infrastructure that developers now take for granted. Reasoning capabilities are on a similar path.
A skeptic might note that most AI deployments are still chatbots and copilots. True, for now. But the enterprises building AI into their backends are already hitting these walls. The pattern is consistent: teams that started asking about orchestration are now asking about accountability, auditability, and cost.
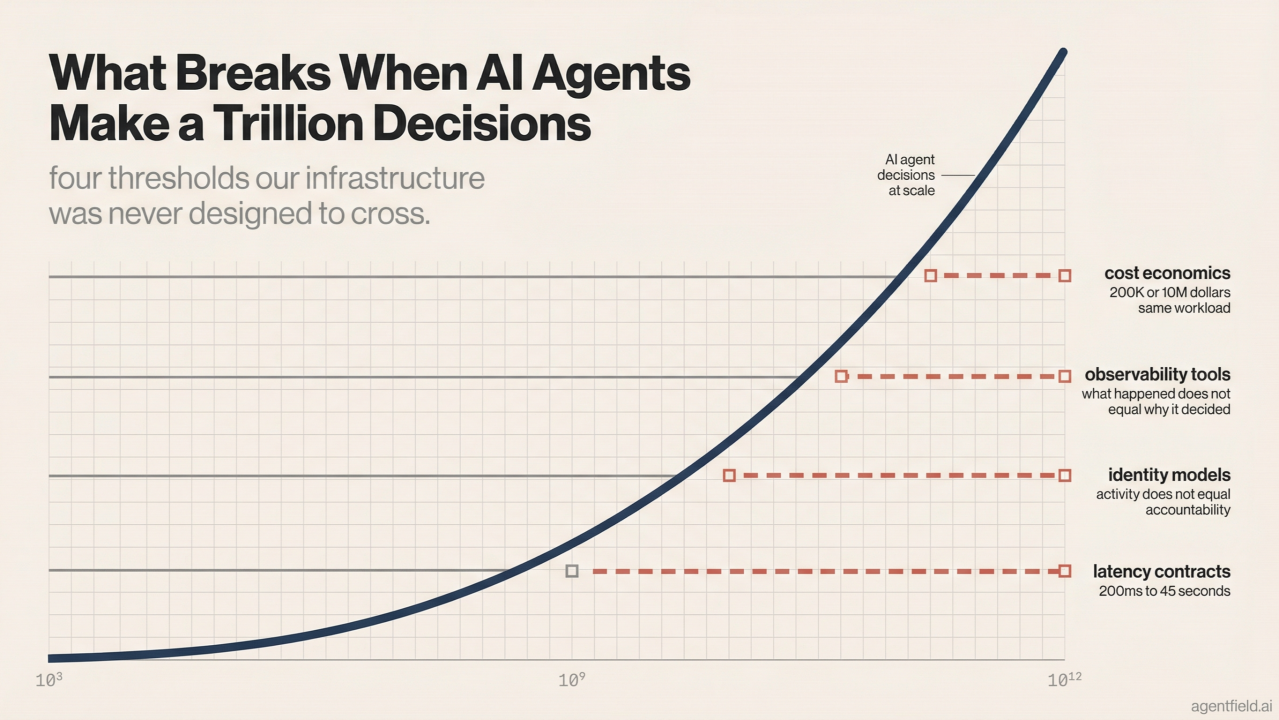
What Breaks: The Math
Latency
Your typical API call has a P99 latency of 200-500 milliseconds. That's the contract your systems are built around. Load balancers, timeouts, circuit breakers: everything assumes responses in that range.
Latency comparison: standard API vs reasoning systems
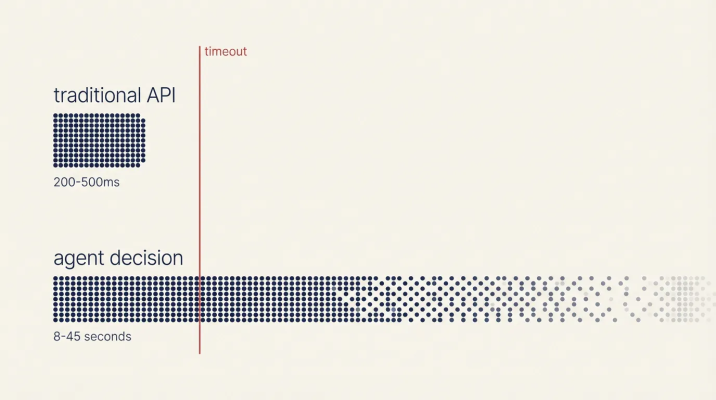
Route that same decision through a reasoning system, and P99 latency changes by an order of magnitude. Based on typical LLM inference times (around 1-3 seconds per reasoning step for capable models), an agent task requiring multiple steps can easily hit 8-45 seconds end-to-end. Your 200ms API becomes an 8-second operation, which means your circuit breakers trip and your timeouts fire before the decision even completes.
Faster inference helps at the margins, but the latency is structural. Reasoning requires iteration, and the architecture has to accommodate that rather than fight it.
Identity
OAuth was designed for human-speed interactions. A user clicks a button, a token validates, a request proceeds. Maybe 10 authenticated requests per minute per user at most. The latency overhead of token validation is invisible at that scale.
Agents operate at machine speed. A single agent task can fan out to thousands of requests as it searches, compares, and verifies. When a single user action cascades into thousands of authenticated calls, the cumulative overhead of token validation turns your auth infrastructure into a bottleneck. The alternative is bypassing it with broad permissions, which means losing accountability entirely.
Try asking "who authorized this decision?" after the fact. The logs exist, but they don't answer the question you're actually asking. Current identity models assume clients that make predictable, bounded requests. They weren't designed for clients that explore possibilities, branch into parallel investigations, and retry with different parameters based on intermediate results. The audit trail ends up showing activity rather than decisions.
Observability
Traditional observability answers "what happened?" Logs record events, traces follow request paths, metrics track aggregates. This works when paths are predictable.
Reasoning systems don't follow predictable paths. The same input can produce different decisions based on context that didn't exist in the previous run, which means asking "what happened?" misses the point entirely. You need to know why.
Debugging these systems with traditional logs feels like archaeology: digging through artifacts after the fact, hoping to reconstruct intent from fragments. What we actually need is decision provenance: the chain of reasoning captured at execution time, not reverse-engineered from scattered events.
Cost
Consider a back-of-envelope calculation: 1 million agent tasks per day, averaging 7 reasoning steps each. At mid-tier API pricing, that's roughly $3 million per month in inference costs. Route those same tasks through frontier reasoning models and the bill climbs to $10 million. Use commodity-tier open-source alternatives and it drops below $200,000. Same workload, same task definitions - 50x cost swing determined entirely by which model handles each step.
The economics get stranger when you realize that not all decisions carry equal weight. A $0.002 call might authorize a $50,000 wire transfer, while a $0.05 call might decide whether to retry a failed notification. Decision economics will become its own discipline, forcing teams to answer questions they've never had to consider: which decisions deserve expensive reasoning, which can be routed to cheaper models, and which reasoning chains should be cached and reused? The CFO is going to need a new line item, and the engineering team is going to need a framework for treating inference as a scarce resource with variable pricing.
The Failure Mode Nobody's Talking About
Portfolio risk across correlated agent decisions
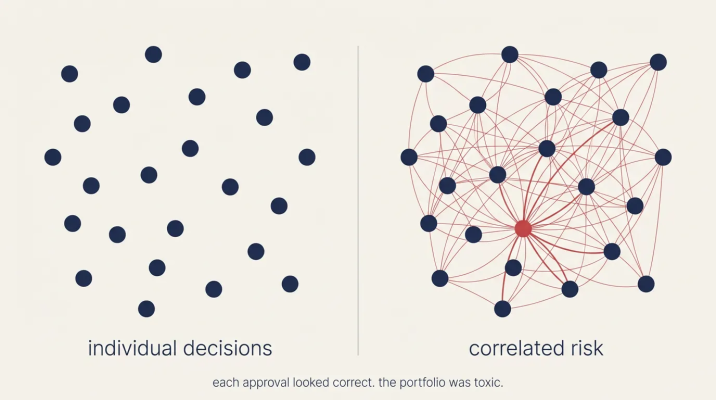
I keep thinking about an agent that approves 50,000 micro-loans in 3 minutes. Each individual decision passes muster: credit check cleared, risk score within bounds, policy constraints satisfied. But the portfolio that emerges is toxic. The correlation risk across those approvals exceeds any reasonable tolerance, and the concentration in a single sector is catastrophic.
No existing log would catch this, and no standard alert would fire, because each approval looks correct when examined in isolation. You'd find out from the CFO a quarter later, when the losses materialize.
This is a different kind of failure than what our infrastructure was built to detect. Databases don't need to care whether queries are related to each other. Message queues don't need to understand the correlation between events they're processing. But decisioning systems have to care about these relationships, because the interactions between decisions can matter more than the decisions themselves.
The Primitives We Don't Have
Four capabilities that existing infrastructure doesn't provide:
Missing infrastructure primitives for AI decision systems
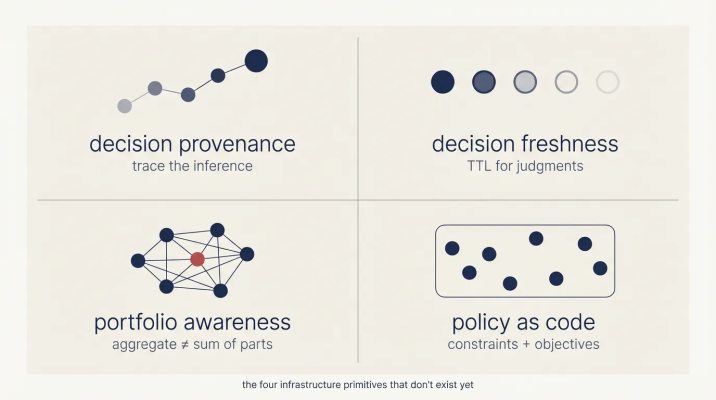
Decision Provenance. Tracing what happened is easy; tracing why something was decided is much harder. Current debugging approaches work backwards from outcomes, hoping to reconstruct intent after the fact. Decision provenance flips this model by capturing the chain of reasoning at execution time, creating records you can query, replay, and defend in an audit.
Decision Freshness. Caches have TTLs (time-to-live) that tell you when data expires. Judgments have no equivalent concept. A routing decision made at 2pm based on current inventory levels may be obsolete by 3pm when stock changes. Yesterday's carrier selection is already stale. We've built sophisticated infrastructure for managing data freshness, but we have nothing comparable for managing the freshness of decisions.
Portfolio Awareness. A thousand loans approved individually might need to be rejected as a batch if their combined risk exceeds tolerance. Each individual decision can be sound while the aggregate is catastrophic. Unlike databases or message queues, decisioning systems need to understand and act on these correlations.
Policy as Code. Business rules are typically deterministic: if X then Y. Policies are different: they express constraints plus objectives, like "minimize delivery time while respecting these boundaries, given this context." They're auditable, versionable, and can be reasoned about formally. This represents a new kind of artifact for a new kind of capability.
These are architectural requirements, not nice-to-have features, for systems that don't exist yet. Someone will build the infrastructure that becomes the default, and everyone else will inherit those design decisions.
Questions for Your Team
If you're building with AI agents, or planning to, ask yourself:
Can you trace a decision? If an agent makes a wrong call at 3am, can you reconstruct not just what happened, but why it decided that? Inputs and outputs aren't sufficient; you need access to the reasoning chain.
Are you treating agent judgments as static data, or do you have expiration logic that accounts for changing context?
If 1,000 agent decisions happen in the same minute, would your monitoring catch systemic risk, or would it only show you individual approvals that each look fine?
For any given agent action, can you cryptographically prove the delegation chain back to human intent?
If you answered "no" to more than one of these, you're building on infrastructure that doesn't exist yet. You're probably not alone. That gap is exactly what we are working on: an AI backend designed for traceable reasoning, expiring judgment, correlated risk, and provable human delegation.