Our engineers use Claude Code as a daily collaborator. It reviews pull requests, writes and runs tests, and iterates on implementations. This is how we build software now.
As an AI-native engineering team, we wanted to abstract the human role upward. Instead of one engineer iterating with one Claude Code session, we wanted dozens of Claude Code instances coordinating in parallel on a shared codebase. We call these instances harnesses: full coding environments with filesystem access, test execution, and git. The goal was to move human responsibility from the iteration loop to the review loop, where an engineer reviews a finished, verified draft pull request rather than guiding each change.
The first time we ran 30+ harnesses in parallel, we got back a pull request that looked correct until we noticed one agent had built its entire API layer on a module another agent never exported. Tests passed because the downstream agent mocked the dependency. Code compiled. PR looked clean. The system did not work. That is the convergence problem: getting N autonomous processes to produce one coherent result requires primitives for isolation, failure recovery, and state reconciliation.
After a few iterations of building and rebuilding, the shift happened. The system now produces draft PRs where code has already been through multiple rounds of automated writing, testing, review, and verification before a human sees it. Only a small percentage of the epics we have run through this pipeline required code changes from the reviewer. Every PR still lands as a draft requiring final human approval, but the human role has moved from line-by-line iteration to architectural sign-off.
We recently open-sourced this system as SWE-AF and ran it on real builds: a diagrams-as-code CLI in Rust (15 issues, 200+ agent invocations, $116), a Go SDK feature (10 issues, 80+ invocations, $19), and a Node.js benchmark where the same architecture scored 95/100 on both the cheapest and mid-tier models. Building SWE-AF forced us to identify which abstractions truly matter for orchestrating AI systems. That work informed AgentField, whose primitives emerged from recurring patterns rather than hypothetical use cases. Two of the most important, a constrained single-shot call (.ai()) and an autonomous harness (.harness()), map directly to the first lesson below.
This article covers the three things we learned that apply to any multi-agent system, plus what we would do differently.
How 200+ Agents Ship One PR

1. You Need Two Modes of LLM Integration, Not One
The most common architectural mistake in multi-agent systems is giving every agent the same kind of LLM access. We made this mistake early.
When every call can use any tool, take any amount of time, and produce any shape of output, you lose the ability to reason about the system operationally. You cannot set SLAs. You cannot predict costs. You cannot even build retry logic, because the meaning of "retry" changes depending on whether you are re-running a 45-minute autonomous loop or re-running a 200ms classification call.
The fix was separating LLM integration into two primitives.
Two Primitives: .ai() vs .harness()

The first is a constrained call: single-shot, structured input and output, no tools, no iteration. It handles routing and classification ("Does this issue need deeper QA?", "Is this change high-risk?") with predictable latency, predictable cost, and outputs that downstream code can switch on. During planning, each issue gets a guidance block:
IssueGuidance:
needs_new_tests: true
estimated_scope: "medium"
touches_interfaces: true
needs_deeper_qa: true
agent_guidance: "Complex parsing logic with edge cases, run QA in parallel"The structured fields drive routing. The agent_guidance string carries context for downstream agents. A call like this costs fractions of a cent and takes milliseconds.
The second is an autonomous loop: multi-turn, tool-using, goal-driven. It receives a goal and a toolset, then iterates until it produces a verifiable outcome. It reads files, writes code, runs tests, discovers failures, and tries again. You check what it delivered, not how it got there. In the diagrams build, a single coder invocation ran up to 150 tool-use turns and cost over $4 on a complex issue.
The constrained call is not a new idea. Every agentic framework has some version of it: a structured prompt, a classification step, a routing decision. It is the common abstraction. In AgentField, we call it .ai(), and it works the way you would expect.
The harness is different. .harness() did not come from studying other frameworks or anticipating what developers might need. It came from watching builds fail. We kept seeing the same pattern: agents needed a full coding environment (filesystem, test runner, git) with an iteration loop that could retry on failure, and no existing abstraction captured that cleanly. The harness emerged from the work itself, not from a design exercise. It is the abstraction we wish we had started with, and it is the one we have not seen elsewhere.
The two coexist in the same system. A single boolean from a cheap .ai() classification call, needs_deeper_qa, determines whether an issue runs through a lean two-call path (coder, then reviewer) or a thorough four-call path (coder, then QA and reviewer in parallel, then synthesizer). The routing is cheap; the work is expensive. Keeping them separate is what makes the system both flexible and cost-efficient.
This is the design philosophy behind AgentField more broadly: we do not invent abstractions and then look for problems they solve. We build systems, watch where they break, and extract the abstractions that keep appearing. .ai() was obvious from day one. .harness() took months of failed builds to recognize.
2. What Happens When Agents Fail (Which They Will, Constantly)
In a 200+ invocation build, failures are the normal path, not edge cases.
Our diagrams-as-code build, a Rust CLI tool with a custom DSL parser, SVG renderer, and ASCII preview mode, had 15 issues across 6 dependency levels. What follows is what actually happened to four of them.
Deadlocks that retrying cannot fix
The integration-tests issue timed out after 2700 seconds. The tests themselves were correct and code review approved them, but the CLI binary they tested had an infinite loop. The inner retry loop ran the same agent on the same binary. The result was the same timeout and the same failure.
The actual iteration record from the build:
{
"iteration": 2,
"action": "block",
"summary": "Issue is stuck in a loop. Tests timeout after 2700s in iteration 2,
same failure as iteration 1 despite attempted CLI binary fix. The test suite is
well-written and passes code review, but the underlying CLI binary hangs or
deadlocks when invoked.",
"qa_passed": false,
"review_approved": true,
"review_blocking": false
}The important detail is review_approved: true alongside qa_passed: false. The tests were good; the code was broken. Retrying would never help because the same agent would produce the same binary with the same deadlock.
There are four possible responses to a failure like this, and three of them are wrong. Retrying harder burns budget (we watched it happen). Aborting the build wastes the 80% of work that already succeeded. Silently dropping the failure ships broken code without anyone knowing. The fourth option, and the one we landed on, is to block the issue, record a typed debt item, and let the rest of the build work around the gap:
{
"type": "dropped_acceptance_criterion",
"criterion": "integration tests pass end-to-end",
"issue_name": "integration-tests",
"severity": "high",
"justification": "CLI binary deadlocks on invocation; test suite correct
but binary needs runtime debugging beyond automated repair"
}This debt record is a typed, severity-rated data structure that downstream agents consume, not a log message. When a dependent issue starts, it receives debt_notes explaining what upstream failed to deliver, so it can work around known gaps instead of building on assumptions that no longer hold.
Review catches that tests miss
The app-module issue told a different story. Iteration 1 produced 119 passing tests and met all acceptance criteria. The QA agent approved. But the code reviewer blocked:
{
"iteration": 1,
"action": "fix",
"summary": "App module is technically sound with all 119 tests passing and all
acceptance criteria met. However, the app module is not exported in lib.rs,
making it inaccessible to library consumers. This violates Rust project
structure conventions.",
"qa_passed": true,
"review_approved": false,
"review_blocking": true
}One missing pub mod app; line in lib.rs. Every test passed, every acceptance criterion was met, but the module was invisible to consumers. The inner loop caught it, and iteration 2 fixed the export with 354 tests passing.
This is the inner retry loop working as intended: a real fix to a real problem that the agent can address on the next attempt.
Regressions on trivial tasks
The project-scaffold issue was the simplest in the build, literally "create Cargo.toml and src/main.rs." It passed on iteration 1 with all 13 tests passing, a successful build, and review approval. Then iteration 2 regressed:
{
"iteration": 2,
"action": "fix",
"summary": "main.rs references 10 non-existent modules, causing cargo build to fail.
This is a regression from iteration 1.",
"qa_passed": false,
"review_approved": false,
"review_blocking": true
}The coder, trying to be helpful, added module declarations for code that did not exist yet. A regression in the simplest issue, on the second try. Autonomous code generation fails in ways you do not predict, even on trivial tasks.
Cascading verification failures
The final-acceptance-verification issue took three iterations to pass. Iteration 1 found four blocking issues: set -e causing script crashes instead of graceful error reporting, macOS-specific stat flags that fail on Linux CI, infinite recursion between test files, and missing dependency checks. Iteration 2 fixed those but introduced a new bug where a cargo fmt check used || true, making it always pass even when code was unformatted. Iteration 3 finally got it right.
The escalation hierarchy
These failures illustrate why a single retry loop is insufficient. The system needs three nested control loops.
Three Nested Control Loops
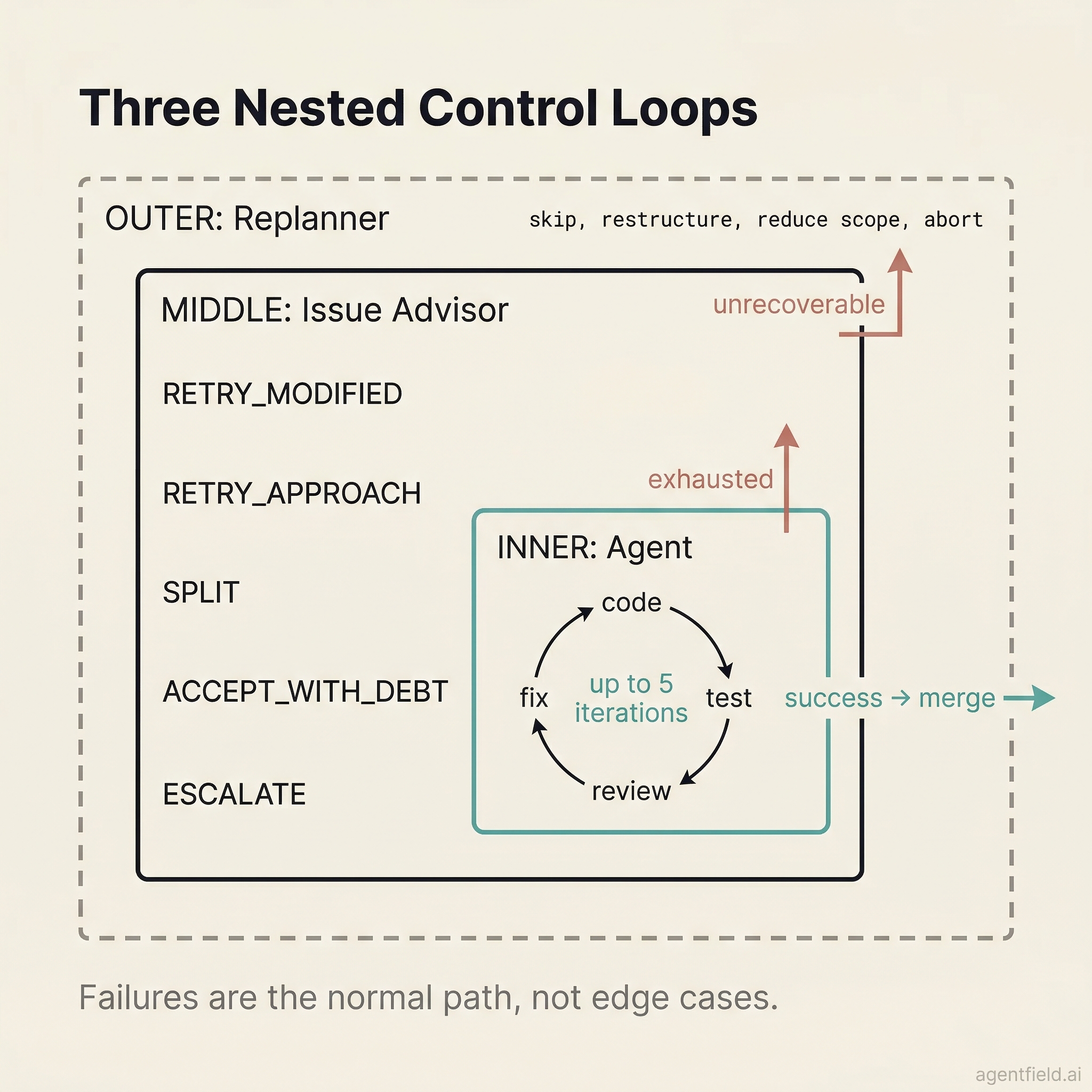
The inner loop runs per issue, up to 5 iterations. The agent retries itself with feedback from QA and review. The app-module's missing export was caught and fixed here. This handles problems that the same agent can solve given better information.
The middle loop is an issue advisor that activates when the inner loop is exhausted. It has five typed recovery actions:
| Action | What happens |
|---|---|
RETRY_MODIFIED | Relax acceptance criteria, record the gap as typed debt |
RETRY_APPROACH | Same criteria, different strategy ("use a different library") |
SPLIT | Break the issue into smaller sub-issues |
ACCEPT_WITH_DEBT | Close enough; record each gap as typed, severity-rated debt |
ESCALATE_TO_REPLAN | Cannot be fixed locally; restructure the remaining work |
On its final invocation, the prompt explicitly warns that this is the last chance, biasing the advisor toward acceptance or escalation rather than another futile retry.
The outer loop is a replanner that fires when issues in a dependency level produce unrecoverable failures. It sees the full execution state and can skip downstream dependents, restructure the remaining issue graph, reduce scope, or abort. Previous replan decisions are fed back on subsequent invocations to prevent repeating failed strategies.
If the replanner itself crashes due to an LLM timeout or malformed output, the system defaults to continue rather than abort. For expensive workflows, graceful degradation is a better default than fail-fast.
The integration-tests deadlock escalated through the inner loop (two failed attempts), then the advisor blocked it and recorded debt. The rest of the build continued. The final PR shipped with an explicit debt section so the reviewer could see what was missing, why it was accepted, and how downstream work adapted.
3. Making $116 Builds Survivable
Our diagrams build ran 200+ agent invocations across 157 log files and cost roughly $116. A crash at invocation 140 cannot mean restarting from invocation 1. Our team comes from high-performance computing, where jobs run for days on shared clusters and any one of them can fail at any time. Checkpointing is not an optimization in that world; it is a survival requirement. We brought the same assumption here: a multi-agent build is a long-running, expensive process, and the infrastructure must treat it that way from the start.
Checkpoint everything
LLM timeouts, rate limits, network errors, and malformed output can each crash a build on their own. At $116 per build, restarting from scratch is not viable.
We checkpoint at every level boundary. This is what the checkpoint captures, taken from the actual checkpoint.json of the diagrams build:
{
"current_level": 3,
"completed_levels": [0, 1, 2],
"all_issues": [
"project-scaffold", "types-module", "error-module",
"lexer", "parser", "validator",
"layout-engine", "svg-renderer", "ascii-renderer",
"smoke-test", "app-module", "cli-module",
"integration-tests", "documentation", "final-acceptance-verification"
],
"original_plan_summary": "15 issues organized in 6 levels that maximize
parallelism while respecting dependencies. Level 0 (1 issue), Level 1
(2 parallel), Level 2 (3 parallel)...",
"replan_count": 0,
"accumulated_debt": [...]
}resume_build() loads the checkpoint, skips completed levels, and continues from the exact failure point. A 30-minute build that fails at minute 25 does not restart from minute 0.
The checkpoint also captures git state (integration branch, original branch, initial commit SHA, worktree directory mapping) so the resumed build can reconstruct the full workspace without re-cloning. Without checkpoint recovery, the probability of some interruption approaches 1 as builds grow longer. Durable execution inverts this relationship: longer workflows accumulate more recovery points, not more fragility.
Isolate agents with git worktrees
Our developers already use git worktrees when working on multiple issues in parallel. Each issue gets its own working directory and branch, so changes stay isolated until they are ready to merge. We applied the same pattern to agents.
How AI Plans Differently
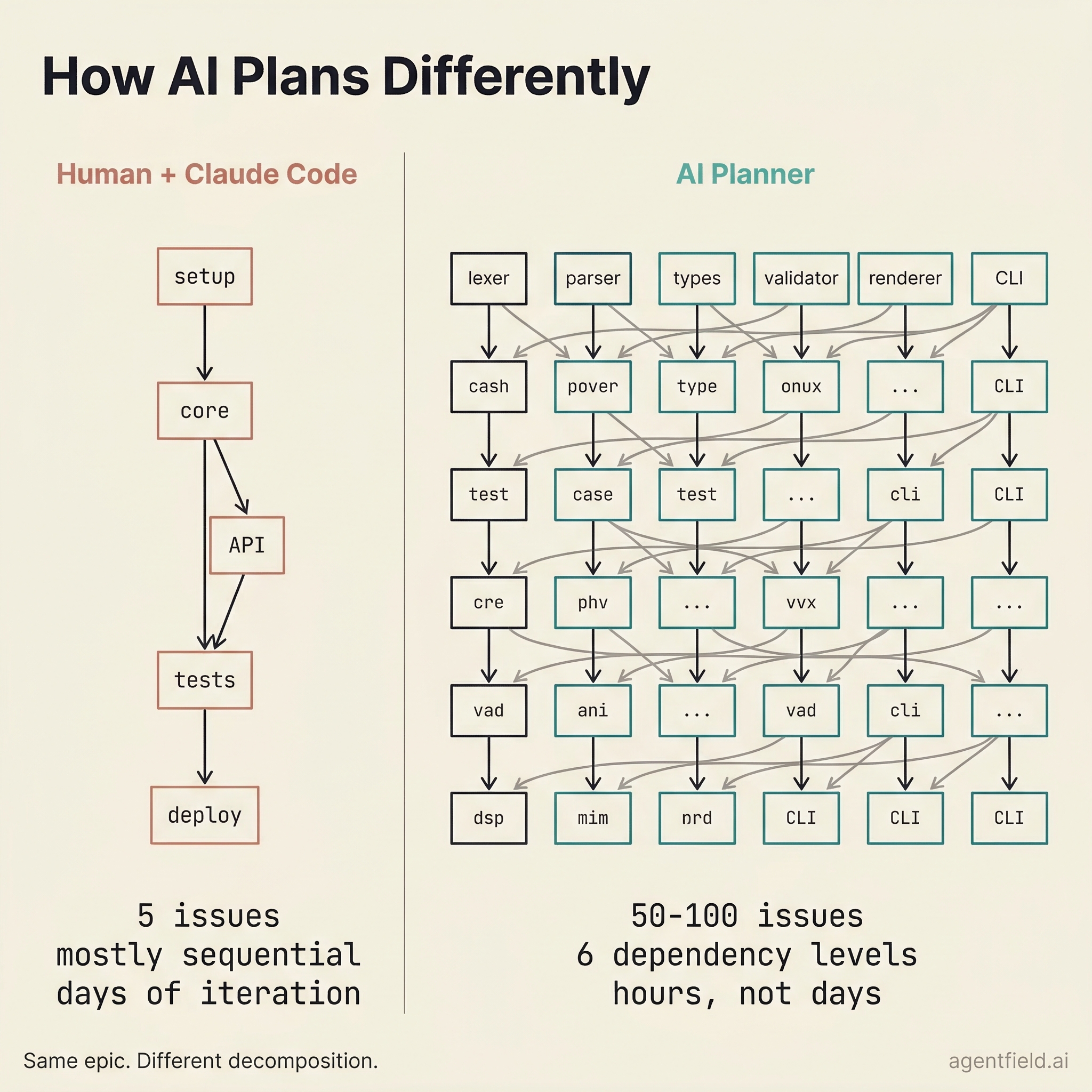
But the agents surprised us in the step before isolation: planning. Given a large epic, the planner consistently produces finer-grained, more parallelizable issue graphs than a human would. We have seen it decompose epics into 50 to 100 issues with dependency structures that a human planner would not attempt because the coordination cost would be too high. That coordination cost is exactly what the system absorbs. A human managing 80 parallel branches is impractical. An orchestrator managing 80 parallel worktrees is a scheduling problem.
Each issue gets a git worktree on a dedicated branch (issue/01-project-scaffold, issue/02-types-module, and so on). In the diagrams build, level 2 ran three issues in parallel (lexer, parser, and validator), each in its own worktree, each modifying different files. There was no lock contention and no conflicts during coding.
Between levels, a merger agent integrates completed branches into the integration branch. The merger is not a mechanical git merge; it reads the architecture spec and file conflict annotations from the planning phase to make intent-aware resolution decisions. When two issues modify the same file (which the planner flagged during _validate_file_conflicts()), the merger understands what each change was trying to accomplish and produces a result that preserves both intents.
The gate sequence between every level enforces a clean handoff:
- Merge gate: integrate completed branches
- Integration test gate: validate that merged code still works together
- Debt gate: process completed-with-debt results, propagate
debt_notesdownstream - Split gate: if any issue was split, inject sub-issues into remaining levels
- Replan gate: if failures escalated, invoke the replanner
- Checkpoint: serialize full state to disk
Every level starts clean. No level inherits dirty state from the previous one. Any gate can pause for human approval in regulated environments; the gate sequence is the same, only the approval policy is configurable.
The one-call interface
This is another pattern that informed AgentField's design. The control plane provides a unified API to reach any agent node attached to it, regardless of runtime or model. The caller does not need to know which agents exist, how many will be spawned, or what failure recovery looks like internally. It hits one endpoint. The control plane handles the rest. This makes the system a backend service that other software can call programmatically, not an interactive tool that waits for a human in the loop. A CI pipeline, a project management integration, or another autonomous system can trigger a full multi-agent build the same way:
All of this (planning, parallel execution, failure recovery, merging, verification) is triggered by a single API call:
curl -X POST http://localhost:8080/api/v1/execute/async/swe-planner.build \
-H "Content-Type: application/json" \
-d '{
"input": {
"goal": "Build a diagrams-as-code CLI tool with DSL parser and SVG output",
"repo_url": "https://github.com/user/my-project",
"config": {
"runtime": "claude_code",
"models": { "default": "sonnet", "coder": "haiku" }
}
}
}'The response is a 202 Accepted with an execution_id. Thirty minutes later, there is a draft PR with the full codebase, test results, and a debt section documenting every scope reduction. The PR body includes the original requirements, the architecture summary, and a complete accounting of every debt item: what was deferred, why, and what downstream impact it had.
Why Architecture Beats Model Selection
Architecture Beats Model Selection
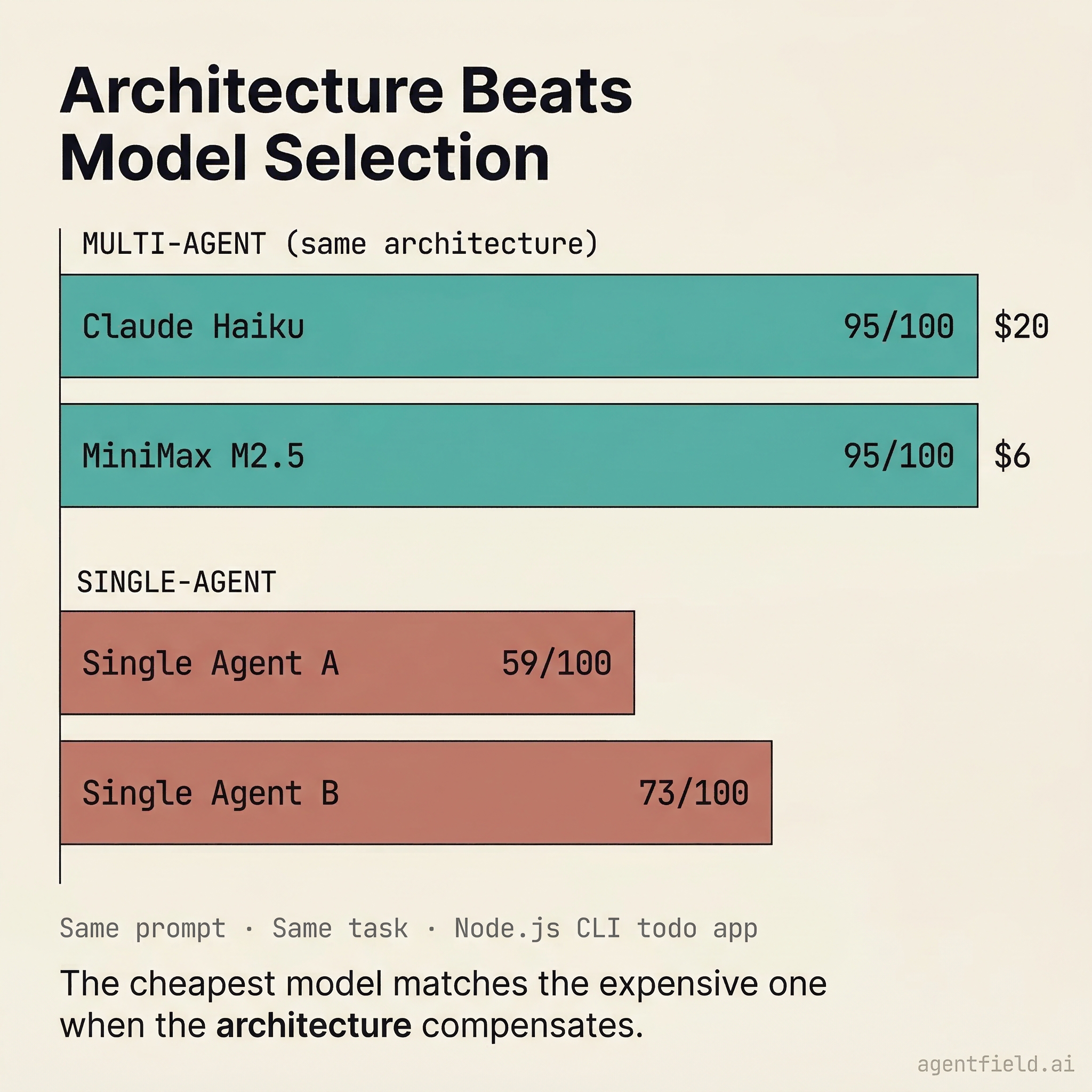
We assumed smarter models would produce better results. They did not.
On a benchmark (Node.js CLI todo app, same prompt across all agents), the same architecture scored 95/100 with both Claude Haiku (the cheapest model in the Claude family, $20 total) and MiniMax M2.5 via OpenRouter ($6 total). Single-agent approaches on the same task scored between 59 and 73.
The model configuration is a flat map:
{
"runtime": "claude_code",
"models": {
"default": "sonnet",
"coder": "haiku",
"qa": "haiku",
"architect": "sonnet"
}
}Swap "coder": "haiku" for "coder": "opus" and re-run. The architecture stays constant; the model is a runtime parameter. Every role (coder, reviewer, QA, planner, merger) can be assigned independently.
The cheapest model matches the expensive one because the verification loops and escalation hierarchy do the work that is commonly attributed to model intelligence. The architecture compensates for model capability through iteration: more inner loop cycles, cheaper per cycle, same outcome.
Each build records which model handled which role, how many iterations each issue required, and the cost breakdown per agent type. The diagrams build data shows the architect at $0.83 for 9 turns (345 seconds), coding agents ranging from $0.50 to $4.26 per invocation depending on issue complexity, and the costliest single agent being QA on integration-tests-reorganize at $4.26. This turns model selection into an empirical question (which model gives the best cost/quality tradeoff for which role) rather than a bet on any single model being smart enough.
What We'd Do Differently
Cross-agent memory is harder than we expected. We maintain a shared key-value store that propagates conventions and failure patterns across issues in a build. When enable_learning=true, conventions discovered by the first successful coder (naming patterns, project structure idioms, testing conventions) reach every subsequent coder. Failure patterns from early issues warn later coders to avoid the same traps. Interface exports from completed issues give downstream coders concrete import paths rather than guesses.
The problem is knowing what to propagate. Too little context and agent 15 repeats agent 1's mistakes. Too much context and the prompt is so long that the agent ignores the actual task. The memory is a simple key-value store with structured schemas, updated synchronously at known lifecycle points. Keeping it simple means it is reliable, but it also means we are manually defining what gets stored and when. We are still tuning the tradeoff between memory breadth and prompt focus.
The verify-fix loop saves builds, but it can mask bad planning. After all issues complete, a verifier agent checks every acceptance criterion from the original requirements against the actual codebase. If anything fails, the system generates targeted fix issues and feeds them back through the execution engine. This is how our Go SDK build hit 34 of 34 acceptance criteria, not by getting everything right on the first pass, but by verifying the outcome and closing gaps automatically.
The downside: the final-acceptance-verification issue in our diagrams build took 3 iterations. First set -e crashes and infinite recursion, then || true making cargo fmt always pass, then finally correct. The verification loop caught all of it. But if you are generating fix issues on every build, the real problem might be upstream in the planner rather than downstream in the verifier. We have started tracking fix-issue frequency as a signal for planning quality, but we have not solved this yet.
200+ invocations at $116 is too expensive for iteration. The diagrams build worked, but the cost per build makes rapid iteration impractical. The architecture is sound (the same control loops scored 95/100 on a $6 model) but we need to be more aggressive about routing low-risk issues to cheaper models and cutting unnecessary QA passes on straightforward work. The architect agent alone cost $0.83 for 9 turns, while a single QA pass on integration test reorganization cost $4.26. There is room to optimize, and we think the right answer is smarter risk-proportional allocation rather than cheaper models across the board.
The Code
SWE-AF and AgentField are both Apache 2.0. The architecture documentation covers the full pattern catalog.
The same orchestration patterns power our other autonomous systems: sec-af for security auditing and cloudsecurity-af for cloud infrastructure security analysis. Same control loops, same failure recovery, different domains.
curl -X POST http://localhost:8080/api/v1/execute/async/swe-planner.build \
-H "Content-Type: application/json" \
-d '{"input": {"goal": "your goal here", "repo_url": "https://github.com/..."}}'